이 블로그에서는 데이터를 병합할 때 사용하는 pandas의 concat() 함수를 다양한 상황에서 어떻게 활용할 수 있는지 살펴보겠습니다.
1. concat() 함수란?
concat() 함수는 pandas 라이브러리에서 제공하는 함수로, 여러 데이터프레임이나 시리즈를 행(row) 또는 열(column) 기준으로 병합할 때 사용됩니다. 이 함수는 같은 구조를 가진 데이터를 연결하여 하나의 데이터프레임으로 만드는 데 자주 사용됩니다.
함수 형태
import pandas as pd
pd.concat(objs, axis=0, join='outer', ignore_index=False, keys=None, levels=None,
names=None, verify_integrity=False, sort=False, copy=True)주요 인자 설명:
- objs: 병합하려는 객체 리스트 (데이터프레임 또는 시리즈).
- axis: 병합 방향. 0은 행 기준 병합(세로 병합), 1은 열 기준 병합(가로 병합).
- join: 데이터 병합 방식. inner는 교집합, outer는 합집합을 기준으로 병합.
- ignore_index: True로 설정하면 기존 인덱스를 무시하고 새로운 인덱스를 생성.
- keys: 병합된 데이터프레임에 상위 레벨 인덱스를 추가하여 구분할 수 있게 함.
2. concat() 함수의 기본 사용법
concat()의 가장 기본적인 사용법은 두 개 이상의 데이터프레임을 행 또는 열 기준으로 병합하는 것입니다. 예제를 통해 기본 사용법을 살펴보겠습니다.
예제 1: 행 기준 병합
import pandas as pd
# 두 개의 데이터프레임 생성
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']})
df2 = pd.DataFrame({'A': ['A3', 'A4', 'A5'],
'B': ['B3', 'B4', 'B5']})
# 행(row) 기준 병합
pd.concat([df1, df2], axis=0)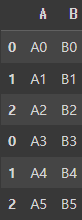
여기서 두 데이터프레임 df1과 df2가 세로로 병합되어 하나의 데이터프레임으로 출력되었습니다. 이때 인덱스가 그대로 유지되므로, 원래의 인덱스가 중복되는 것을 볼 수 있습니다.
기본 default 값은 axis=0이기 때문에 세로 방향으로 병합할 땐, aixs를 스킵하셔도 됩니다.
예제 2: 열 기준 병합
# 열(column) 기준 병합
pd.concat([df1, df2], axis=1)
이 경우에는 두 데이터프레임이 가로로 병합되었습니다.
3. concat()의 다양한 옵션
(1) 인덱스 무시하기
기본적으로 concat()은 원래의 인덱스를 유지합니다. 하지만 ignore_index=True 옵션을 사용하면 인덱스를 다시 설정할 수 있습니다.
pd.concat([df1, df2], ignore_index=True)
(2) 병합 방식 선택: Inner Join vs. Outer Join
concat()은 기본적으로 outer join(합집합)을 사용합니다. 하지만 join='inner' 옵션을 통해 교집합만 병합할 수도 있습니다.
# 데이터프레임에 서로 다른 열 추가
df3 = pd.DataFrame({'A': ['A0', 'A1'],
'C': ['C0', 'C1']})
pd.concat([df1, df3], axis=1, join='inner')
이처럼 inner join을 사용하면 두 데이터프레임에 공통으로 존재하는 열만 병합됩니다.
concat()과 merge()의 차이점
pandas.concat()과 pandas.merge() 모두 데이터를 병합하는 데 사용되지만, 그 목적과 동작 방식에서 차이가 있습니다.
concat()의 주요 특징
- 단순 병합: concat()은 여러 데이터프레임을 행(axis=0) 또는 열(axis=1) 기준으로 병합하는 데 주로 사용됩니다.
- 계층적 인덱스 지원: keys 옵션을 통해 계층적 인덱스를 쉽게 추가할 수 있어, 병합된 데이터프레임의 출처를 알 수 있습니다.
- 결합할 기준이 없음: concat()은 인덱스나 열을 기준으로 매칭하는 것이 아니라, 그냥 이어붙이는(append-like) 방식입니다.
반면 merge는 sql의 join과 같은 역할을 하는 함수이며, 단순히 이어붙이는 방식이 아닌, 매칭되는 데이터만 필터링하여 이어붙이는 방식입니다. merge() 함수에 대한 자세한 설명은 이 글을 참고해주세요.
4. 시리즈와 함께 사용하기
concat()은 데이터프레임뿐만 아니라 시리즈와도 함께 사용할 수 있습니다. 시리즈를 데이터프레임과 병합할 때도 동일한 방식으로 사용할 수 있습니다.
s1 = pd.Series(['X0', 'X1', 'X2'], name='X')
pd.concat([df1, s1], axis=1)
5. 추가 옵션 설명
pandas의 concat() 함수는 다양한 상황에서 유연하게 데이터 병합을 지원하는 여러 옵션을 제공합니다. 이 중 일부 고급 옵션들은 특정 상황에서만 유용하게 사용될 수 있습니다. 아래에서 keys, levels, names, verify_integrity, sort, copy 옵션에 대해 설명하겠습니다.
(1) keys=None
- 설명: 이 옵션은 병합된 각 데이터프레임이나 시리즈를 구분할 수 있도록 계층적 인덱스(hierarchical index, 멀티인덱스)를 생성할 때 사용됩니다.
- 활용 사례: 여러 데이터프레임을 하나로 병합했을 때, 각각의 원본 데이터프레임이 어디에서 왔는지 구분하고 싶을 때 사용됩니다.
# keys 옵션 사용 예시
pd.concat([df1, df2], keys=['df1', 'df2'])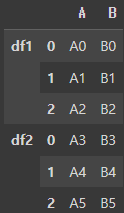
keys=['df1', 'df2']는 각 데이터프레임을 구분하는 상위 인덱스를 추가하는 역할을 합니다.
(2) levels=None
- 설명: keys와 함께 사용되며, 계층적 인덱스의 레벨 값을 명시적으로 정의할 때 사용됩니다. 주로 복잡한 계층 구조를 구성할 때 유용합니다.
- 활용 사례: 병합할 때 인덱스의 특정 레벨을 수동으로 설정하고 싶을 때 사용됩니다.
pd.concat([df1, df2], keys=['df1', 'df2'], levels=[['df1', 'df2']])
(3) names=None
- 설명: 계층적 인덱스의 각 레벨에 대해 이름을 지정할 수 있습니다. keys를 사용하여 계층적 인덱스를 만들었다면, names를 통해 각 인덱스 레벨의 이름을 설정할 수 있습니다.
- 활용 사례: 계층적 인덱스의 각 레벨에 이름을 지정해 이해하기 쉽게 만들고 싶을 때 사용됩니다.
pd.concat([df1, df2], keys=['df1', 'df2'], names=['DataFrame'])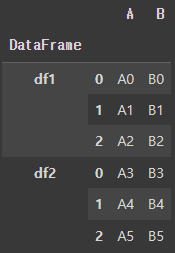
여기서 names=['DataFrame']을 사용해 계층적 인덱스의 이름을 설정했습니다.
(4) verify_integrity=False
- 설명: 이 옵션이 True로 설정되면 병합할 때 중복된 인덱스가 있는지 확인합니다. 만약 중복된 인덱스가 있다면 오류를 발생시킵니다.
- 활용 사례: 병합 과정에서 인덱스가 중복되지 않도록 강제할 때 사용됩니다.
# verify_integrity=True로 중복 인덱스를 허용하지 않음
pd.concat([df1, df2], verify_integrity=True) # 오류 발생 가능(5) sort=False
- 설명: 병합할 때 열이나 인덱스를 자동으로 정렬할지 여부를 결정합니다. 기본값은 False로, 정렬되지 않고 병합됩니다.
- 활용 사례: 데이터 병합 시 열이나 인덱스가 임의로 정렬되는 것을 방지하고 싶을 때 사용됩니다. True로 설정하면 자동 정렬이 됩니다.
(6) copy=True
- 설명: copy=True로 설정하면, 데이터가 병합될 때 원본 데이터를 복사한 후 병합됩니다. 만약 copy=False로 설정하면 데이터는 원본을 공유합니다.
- 활용 사례: 데이터의 사본을 사용해 병합하고 싶을 때 True, 메모리를 절약하고 원본 데이터를 그대로 병합하고 싶을 때 False로 설정합니다.
참고
pandas.concat — pandas 2.2.3 documentation
If True, do not use the index values along the concatenation axis. The resulting axis will be labeled 0, …, n - 1. This is useful if you are concatenating objects where the concatenation axis does not have meaningful indexing information. Note the index
pandas.pydata.org
'데이터분석 > Pandas' 카테고리의 다른 글
| [Python] Pandas : Dataframe 함수 - melt() (0) | 2024.09.29 |
|---|---|
| [Python] Pandas : Dataframe 함수 - pivot() vs pivot_table() (1) | 2024.09.29 |
| [Python] Pandas : Dataframe 함수 - merge() (0) | 2024.08.16 |
| [Python] Pandas : DataFrame 함수 - loc, iloc (0) | 2024.08.11 |
| [Python] Pandas : Dataframe 함수 - groupby() 사용법 (0) | 2024.07.27 |




댓글