Ppivot()과 pivot_table() 함수는 엑셀의 피벗테이블과 같은 기능을 제공하는 함수입니다. 두 함수는 매우 유사해 보이지만, 실제로는 용도와 기능에서 몇 가지 중요한 차이점이 있습니다. 이번 포스트에서는 이 두 함수의 사용법과 차이점을 살펴보겠습니다.
1. Pandas pivot() 함수
pivot() 함수는 데이터를 재구성하여 열 값을 인덱스로, 열로, 값으로 변환합니다. 이는 고정된 값들에 대해 단순한 피벗을 만들 때 사용됩니다.
pivot() 함수 문법
DataFrame.pivot(index=None, columns=None, values=None)
- index: 새로 설정할 인덱스. 기존의 열 이름을 지정합니다.
- columns: 열로 사용할 데이터. 피벗 테이블의 새로운 컬럼으로 변환됩니다.
- values: 데이터 값으로 사용할 열. 이 값이 새롭게 생성된 인덱스와 열의 교차점에 배치됩니다.
pivot() 함수 예시
import pandas as pd
# 예시 데이터 생성
df = pd.DataFrame({
'Date': ['2023-01-01', '2023-01-01', '2023-01-02', '2023-01-02'],
'City': ['Seoul', 'Busan', 'Seoul', 'Busan'],
'Temperature': [10, 5, 11, 6]
})
# pivot 함수로 데이터 변환
df.pivot(index='Date', columns='City', values='Temperature')
| Date | City | Temperature |
| 2023-01-01 | Seoul | 10 |
| 2023-01-01 | Busan | 5 |
| 2023-01-02 | Seoul | 11 |
| 2023-01-02 | Busan | 6 |
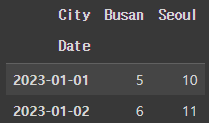
- index='Date': 날짜를 인덱스로 설정
- columns='City': 도시명을 열로 설정
- values='Temperature': 온도 값을 새롭게 구성된 테이블의 값으로 설정
pivot() 함수는 단순한 피벗 변환에 매우 유용합니다. 하지만, 이 함수는 중복된 인덱스와 열을 허용하지 않으며, 동일한 인덱스-열 쌍이 두 개 이상 있으면 오류가 발생합니다.
2. Pandas pivot_table() 함수
pivot_table() 함수는 더 복잡한 피벗 테이블을 생성하는 데 사용되며, 집계 함수를 지원합니다. 중복된 데이터가 있을 경우 평균, 합계, 개수 등의 집계를 수행할 수 있는 유용한 기능을 제공합니다.
pivot_table() 함수 문법:
DataFrame.pivot_table(index=None, columns=None, values=None, aggfunc='mean', fill_value=None, margins=False)- index: 새로운 인덱스로 사용할 열.
- columns: 피벗 테이블의 열로 사용할 데이터.
- values: 값으로 사용할 열.
- aggfunc: 데이터가 중복될 경우 사용할 집계 함수(기본값: 'mean').
- fill_value: 결측값을 대체할 값.
- margins: 집계 결과에 총계를 추가할지 여부.
pivot_table() 함수 예시
(1) 집계함수 사용
import pandas as pd
# 예시 데이터 생성
df = pd.DataFrame({
'Date': ['2023-01-01', '2023-01-01', '2023-01-02', '2023-01-02', '2023-01-01', '2023-01-01', '2023-01-02', '2023-01-02'],
'City': ['Seoul', 'Busan', 'Seoul', 'Busan', 'Seoul', 'Busan', 'Seoul', 'Busan'],
'Temperature': [10, 5, 11, 6, 15, 10, 13, 12],
'Humidity': [30, 60, 35, 65, 50, 70, 60, 80]
})
# pivot_table 함수로 데이터 변환
df.pivot_table(index='Date', columns='City', values='Temperature', aggfunc='mean')
위의 결과는 pivot()과 비슷하지만, 중복된 데이터를 처리할 수 있다는 점에서 pivot_table()이 더 유연합니다. 위 예시처럼 같은 Date와 City에 대해 여러 값이 있다면 aggfunc='mean'을 통해 평균값이 계산됩니다.
(2) 여러집계 함수 사용
# 여러 집계 함수 사용
df.pivot_table(index='Date', columns='City', values=['Temperature', 'Humidity'], aggfunc=['mean', 'sum'])
- aggfunc=['mean', 'sum']: Temperature와 Humidity에 대해 평균과 합계를 동시에 계산.
- 결과는 계층적으로 나타나며, 각 집계 함수가 별도의 열로 나옵니다.
(3) fill_value 옵션: 결측값(NaN)을 대체하기
피벗 테이블을 만들 때 결측값(NaN)이 발생할 수 있습니다. fill_value 옵션을 사용하면 결측값을 원하는 값으로 대체할 수 있습니다.
# 예시 데이터 생성 (Busan의 온도 데이터 일부 결측)
df_with_nan = pd.DataFrame({
'Date': ['2023-01-01', '2023-01-01', '2023-01-02', '2023-01-02'],
'City': ['Seoul', 'Busan', 'Seoul', 'Busan'],
'Temperature': [10, None, 11, None],
'Humidity': [30, 60, 35, 65]
})
# 결측값을 0으로 대체
df_with_nan.pivot_table(index='Date', columns='City', values='Temperature', fill_value=0, dropna=False)

- fill_value=0: 결측값을 0으로 대체.
- 온도 데이터에 결측값이 있을 때, 해당 값을 0으로 대체하여 피벗 테이블을 완성.
참고로, dropna 옵션은 default 값이 True이기 때문에 False로 바꿔주어야 Busan 열이 사라지는 걸 방지할 수 있습니다.
(4) margins 옵션: 총계(합계) 행/열 추가하기
총계를 계산할 때 margins=True 옵션을 사용하면, 각 행과 열의 합계가 추가됩니다. 이는 전체 데이터의 통계를 보고 싶을 때 유용합니다.
# 총계 행과 열을 추가한 pivot_table
df.pivot_table(index='Date', columns='City', values='Temperature', aggfunc='mean', margins=True)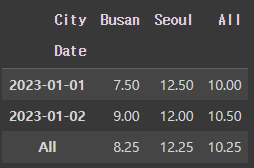
- margins=True: 총계 행과 열을 추가.
- All이라는 이름의 총계가 생성되며, 각 행과 열의 평균 값이 계산됩니다.
3. pivot()과 pivot_table()의 차이점
1) 중복 데이터 처리
- pivot()은 중복된 인덱스-열 쌍을 허용하지 않으며, 만약 중복된 데이터가 있을 경우 오류가 발생합니다.
- pivot_table()은 집계 함수(aggfunc)를 사용하여 중복 데이터를 처리할 수 있습니다. 기본적으로 평균을 사용하지만, 합계, 개수 등 다양한 집계 함수를 지정할 수 있습니다.
2) 집계 함수 지원
- pivot()은 단순한 피벗 테이블을 만들 때 유용하지만, 집계 함수는 제공하지 않습니다.
- pivot_table()은 중복된 값이 있을 때, 이를 처리할 수 있는 집계 함수를 지원합니다.
3) 결측값 처리
- pivot()에서는 결측값을 자동으로 처리하지 않으며, NaN이 그대로 남습니다.
- pivot_table()에서는 fill_value를 지정하여 결측값을 처리할 수 있습니다.
4) 다중 값 처리
- pivot()은 단일 값만 피벗할 수 있습니다.
- pivot_table()은 다중 값을 처리할 수 있습니다. 즉, 여러 열을 값으로 지정하고 이를 집계할 수 있습니다.
4. pivot()과 pivot_table() 비교 요약
| 기능 | pivot() | pivot_table() |
| 중복 데이터 처리 | 허용되지 않음 (오류 발생) | aggfunc로 중복 데이터 처리 가능 (평균, 합계 등) |
| 집계 함수 | 지원하지 않음 | aggfunc 매개변수로 집계 가능 |
| 결측값 처리 | 결측값을 자동으로 처리하지 않음 | fill_value로 결측값 대체 가능 |
| 다중 값 처리 | 하나의 열만 값으로 변환 | 여러 열을 집계 가능 |
| 성능 | 간단한 데이터 변환에 적합 | 복잡한 데이터와 집계 작업에 적합 |
5. 어떤 경우에 어떤 함수를 사용해야 할까?
- pivot() 사용 시점:
- 중복된 값이 없고, 단순한 피벗 테이블이 필요할 때.
- 여러 값이 겹치지 않는 데이터를 쉽게 재구조화할 때.
- pivot_table() 사용 시점:
- 데이터에서 중복된 항목이 존재하고, 이를 처리할 집계 함수가 필요할 때.
- 결측값 처리가 필요하거나, 다양한 통계 집계가 필요한 경우.
- 다중 값 피벗이 필요할 때.
6. 결론
pivot()과 pivot_table() 함수는 데이터 변환에서 중요한 역할을 하지만, 각각의 사용 용도는 다릅니다. pivot()은 간단한 데이터 구조 변경에 적합하지만, 중복된 값이 있으면 오류가 발생할 수 있습니다. 반면에 pivot_table()은 중복 데이터를 집계하고 다양한 집계 함수를 지원하는 등 더 복잡한 데이터를 처리할 수 있는 유연한 함수입니다. 따라서 데이터에 중복이 있거나 집계가 필요한 경우에는 pivot_table()을 사용하는 것이 더 적합합니다.
참고
'파이썬' 카테고리의 다른 글
| 파이썬 퀀트투자(1): 최근 영업일 기준 데이터 크롤링 (7) | 2024.10.09 |
|---|---|
| [Python] Pandas : Dataframe 함수 - melt() (0) | 2024.09.29 |
| [Python] Pandas : Dataframe 함수 - concat() (0) | 2024.09.29 |
| Python 개발환경 설정 (3) | 2024.09.11 |
| [Python] Pandas : Dataframe 함수 - merge() (0) | 2024.08.16 |



댓글