이 글에서는 python의 대표적인 데이터 관련 함수인 groupby의 원리, 사용법에 대해서 알아보겠습니다. 대표적으로 사용하는 인자와 집계 함수의 종류와 예시도 살펴보겠습니다.
groupby 함수는 데이터프레임을 그룹으로 분할하고 각 그룹에 대해 연산을 적용할 수 있습니다. SQL의 GROUP BY와 똑같은 기능을 합니다. 이 함수는 데이터를 그룹화하고 그룹화된 데이터를 다양한 방법으로 분석하고 처리하는 데 사용됩니다. groupby 함수의 작동 방식은 아래와 같이 분할 -> 적용 -> 결합 단계를 거치게 됩니다.
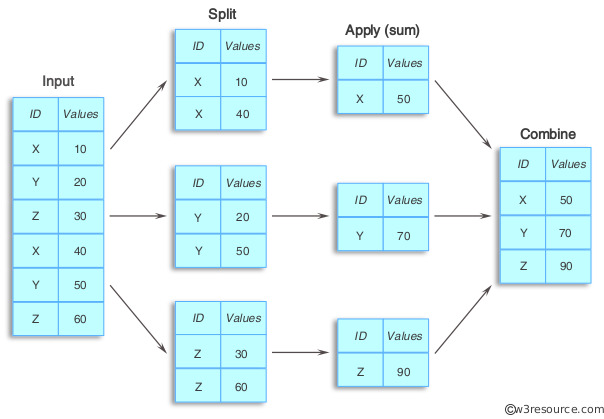
- 분할(Splitting):
- groupby 함수는 데이터프레임을 기준 열(또는 열의 리스트)에 따라 그룹으로 분할합니다.
- 이 기준 열의 값에 따라 데이터가 여러 그룹으로 나뉩니다.
- 적용(Applying):
- 분할된 각 그룹에 대해 적용할 함수(예: 집계, 변환, 필터링)를 지정할 수 있습니다.
- apply, agg, transform 등의 함수를 사용하여 그룹화된 데이터에 연산을 적용할 수 있습니다.
- 결합(Combining):
- 각 그룹에 대해 적용된 함수의 결과를 하나의 결과로 결합하여 새로운 데이터프레임을 생성합니다.
- 결과 데이터프레임의 형태는 적용된 함수에 따라 달라질 수 있습니다.
groupby 함수를 사용할 때는 일반적으로 다음 단계를 따릅니다:
- 기준 열 선택:
- 데이터를 어떤 열을 기준으로 그룹화할 것인지 선택합니다.
- 그룹화:
- 선택한 기준 열을 사용하여 데이터를 그룹화합니다.
- 연산 적용:
- 각 그룹에 대해 적용할 연산(예: 집계, 변환)을 선택하고 적용합니다.
- 결과 확인:
- 적용된 연산의 결과로 생성된 새로운 데이터프레임을 확인합니다.
예를 들어, 다음은 groupby 함수를 사용하여 데이터를 그룹화하고 각 그룹의 평균을 계산하는 간단한 예시입니다:
import seaborn as sns
# 타이타닉 데이터 불러오기
df = sns.load_dataset('titanic')
# 생존여부를 기준으로 평균적으로 요금을 얼마나 지불했는지
df.groupby('survived')['fare'].mean()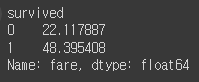
이 코드는 'survived' 열을 기준으로 데이터를 그룹화하고 각 그룹에서 'fare' 열의 평균을 계산합니다. 이 코드를 SQL 문법으로 변경하면 아래와 같습니다.
SELECT survived, MEAN(fare)
FROM df
GROUP BY survived;
groupby() 함수의 괄호 안에 들어갈 수 있는 인자와 함께 흔히 함께 쓰이는 함수들에 대해 알아보겠습니다.
- by: 데이터를 그룹화할 기준이 되는 열의 이름이나 열의 리스트입니다. 이 인자를 사용하여 그룹화할 열을 지정합니다.
- axis: 그룹화할 축을 지정합니다. 0은 인덱스(행)를 기준으로 그룹화하고, 1은 열을 기준으로 그룹화합니다. 기본값은 0입니다.
- level: 계층적 인덱스를 기준으로 그룹화할 경우 사용됩니다. 기본값은 None으로, 단일 인덱스를 기준으로 그룹화합니다.
- as_index: 그룹화한 열을 인덱스로 사용할지 여부를 결정합니다. 기본값은 True로, 그룹화한 열이 인덱스로 사용됩니다. False로 설정하면 인덱스를 다시 만들지 않습니다.
- sort: 그룹화된 결과를 정렬할지 여부를 결정합니다. 기본값은 True로, 정렬됩니다.
- group_keys: 그룹 키를 인덱스의 이름으로 추가할지 여부를 결정합니다. 기본값은 True로, 인덱스의 이름에 그룹 키가 포함됩니다.
groupby() 함수는 일반적으로 그룹화된 데이터에 대해 다양한 연산을 수행합니다. 이때 사용되는 몇 가지 흔한 함수들은 다음과 같습니다:
- mean(): 각 그룹의 평균을 계산합니다.
- sum(): 각 그룹의 합을 계산합니다.
- count(): 각 그룹의 요소 개수를 계산합니다.
- max(): 각 그룹의 최댓값을 계산합니다.
- min(): 각 그룹의 최솟값을 계산합니다.
- size(): 각 그룹의 크기를 계산합니다(결과는 그룹당 요소의 개수)
- std(): 각 그룹의 표준편차를 계산합니다.
- var(): 각 그룹의 분산을 계산합니다.
이 외에도 사용자가 정의한 사용자 정의 함수를 agg() 메서드를 사용하여 그룹화된 데이터에 적용할 수 있습니다.
연산 함수 예시
1. mean()
df.groupby('survived')['fare'].mean()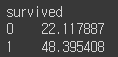
만약 2개의 열을 기준으로 그룹화하고 싶다면 아래와 같이 코드를 작성할 수 있습니다.
df.groupby(['survived','sex'])['fare'].mean()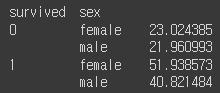
2. sum()
df.groupby('survived')['fare'].sum()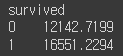
3. count()
df.groupby('survived')['fare'].count()

4. max()
df.groupby('survived')['fare'].max()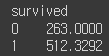
5. agg()
# 사용자 정의 함수를 적용하여 그룹화된 데이터에 적용하기
def custom_function(x):
return x.max() - x.min()
df.groupby('survived')['fare'].agg(custom_function)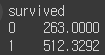
더 간단하게는 아래와 같이 코드를 작성해도 똑같은 결과가 나옵니다.
df.groupby('survived')['fare'].agg(lambda x: x.max() - x.min())
.agg()를 사용하면 다중 통계량도 구할 수 있습니다.
df.groupby(['survived')['fare'].agg(['mean', lambda x : x.max() - x.min()])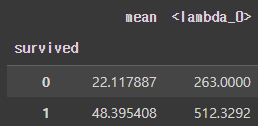
컬럼 이름이 거슬린다면, 아래와 같이 rename() 함수를 사용해주면 됩니다.
df.groupby(['survived'])['fare'].agg(['mean', lambda x : x.max() - x.min()]).rename(columns = {'<lambda_0>': 'range'})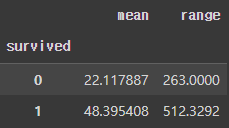
컬럼 별로 다른 집계함수를 사용하고 싶다면 아래와 같이 코드를 작성하면 됩니다.
df.groupby(['survived', 'sex']).agg({'fare':'mean', 'age':'max'})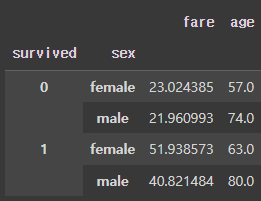
참고로 .agg() 함수 대신 .apply() 함수를 사용할 수도 있습니다.
인자 예시
1. as_index=False
groupby의 기준이 되는 열을 인덱스로 사용하지 않고, 컬럼으로 만들고 싶을 때 as_index=False 를 사용하면 됩니다.
df.groupby(['survived', 'sex'],as_index=False).agg({'fare':'mean', 'age':'max'})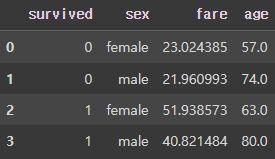
참고로, .reset_index()의 함수를 사용해도 똑같은 결과가 나옵니다.
df.groupby(['survived', 'sex']).agg({'fare':'mean', 'age':'max'}).reset_index()
2. dropna = False
SQL에서는 group by 기준으로 설정한 컬럼에 null 값이 있으면, null 값을 기준으로도 집계를 해줍니다. 하지만 파이썬의 groupby()함수는 null값을 아예 제외시켜버립니다. 이럴 때, null 값까지 포함해서 집계를 하고 싶다면 dropna=False 인자를 사용하면 됩니다. 예시를 들어보겠습니다.
# 예시 데이터 생성
import numpy as np
import pandas as pd
data = {
'index' : ['A', 'A', 'A', np.nan, 'B', 'B', 'B'],
'value' : [1,2,3,4,5,6,7]
}
df = pd.DataFrame(data)
df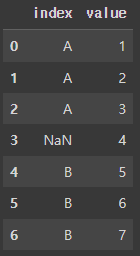
여기서 일반적인 groupby 함수를 사용하면 결과가 이렇게 나옵니다.
df.groupby('index').mean()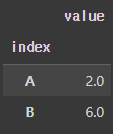
하지만 dropna=False 인자를 사용하면 다음과 같은 결과가 나옵니다.
df.groupby('index',dropna=False).mean()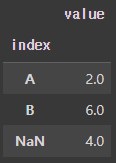
3. level
위에서 살펴보았던 예시 중에 결과가 멀티 인덱스로 출력되는게 있었습니다. 이 결과에서 다시 'sex' 인덱스를 기준으로 그룹바이하여 집계를 하고 싶다면 어떻게 해야할까요?
df = df.groupby(['survived', 'sex'],dropna=False).agg({'fare':'mean', 'age':'max'})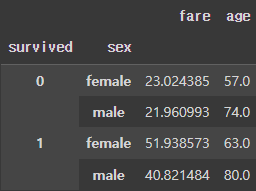
이럴 땐, level 인자를 사용하면 됩니다.
df.groupby(level=1).sum()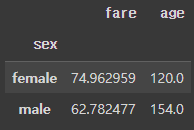
여기까지 python의 groupby 함수에 대해서 알아보았습니다.
참고
'파이썬' 카테고리의 다른 글
| [Python] Pandas : Dataframe 함수 - merge() (0) | 2024.08.16 |
|---|---|
| [Python] Pandas : DataFrame 함수 - loc, iloc (0) | 2024.08.11 |
| [Python] Pandas : Dataframe 함수 - reset_index() (0) | 2024.06.09 |
| [Python] Pandas : Dataframe 함수 - replace() (1) | 2024.06.09 |
| BeautifulSoup을 이용한 정적 크롤링 개념 정리 및 실습 (1) | 2024.03.15 |




댓글