이 블로그 포스트에서는 pandas의 인덱싱 기능인 loc과 iloc에 대해 깊이 있게 다룹니다. loc과 iloc의 차이점, 사용 방법, 그리고 실제 데이터 분석 작업에서 어떻게 활용할 수 있는지에 대한 다양한 예시를 제공합니다.
loc과 iloc 설명
- loc: "label-based location"의 약자입니다. 이 명칭에서 알 수 있듯이, loc은 데이터프레임에서 라벨(label), 즉 행과 열의 이름을 기반으로 데이터를 선택하는 방식입니다.
loc은 DataFrame의 행과 열을 라벨을 통해 접근할 때 사용됩니다. 기본적인 문법은 다음과 같습니다.
df.loc[row_label, column_label]- iloc: "integer location"의 약자입니다. iloc은 정수 인덱스(integer location)를 기반으로 데이터를 선택하는 방식입니다. 여기서 인덱스는 데이터프레임에서 행과 열의 위치를 나타내는 0부터 시작하는 숫자입니다.
iloc은 DataFrame의 행과 열을 정수 인덱스로 접근할 때 사용됩니다. 기본적인 문법은 다음과 같습니다.
df.iloc[row_index, column_index]
loc, iloc 둘다 첫번째 요소에는 '행'이 들어가고, 두 번째 요소에는 '열'이 들어갑니다. 만약 '열'을 생략하는 경우 무조건 '행'을 기준으로 데이터를 선택하게 됩니다. 이 규칙을 잘 기억해두셔야합니다.
ex) df.loc[1] <- 이 경우 df 전체 열에 대한 1번째 행 선택.
loc과 iloc의 장점
df.loc와 df.iloc는 pandas에서 DataFrame의 데이터를 선택, 필터링, 수정할 때 강력한 도구로, 다양한 상황에서 효율적이고 유연한 접근을 제공합니다. 이 두 인덱서를 사용하면 얻을 수 있는 주요 이점들을 정리해 보겠습니다.
1. 명확한 데이터 접근 방식
- df.loc: 라벨 기반 인덱싱으로, 데이터 프레임의 행과 열 라벨(이름)을 사용하여 데이터를 선택할 수 있습니다. 이로 인해 특정 열 이름이나 인덱스를 사용하는 경우 코드가 더 직관적이고 읽기 쉽게 됩니다.
# 특정 라벨을 기준으로 데이터를 선택
df.loc[0, 'age'] # 첫 번째 행의 'age' 열 데이터- df.iloc: 정수 위치 기반 인덱싱으로, 0부터 시작하는 정수 인덱스를 사용하여 데이터를 선택합니다. 데이터의 물리적 위치를 기준으로 데이터를 선택할 수 있어, 데이터를 직접 조작하거나 특정 위치에 기반한 접근이 필요할 때 유용합니다.
# 특정 위치를 기준으로 데이터를 선택
df.iloc[0, 1] # 첫 번째 행의 두 번째 열 데이터
2. 슬라이싱 기능
- 두 인덱서는 슬라이싱을 지원하여 행과 열을 부분적으로 선택할 수 있습니다. 특히 loc은 라벨 기반 슬라이싱을 제공하며, iloc은 정수 기반 슬라이싱을 제공합니다. 이는 대규모 데이터셋을 부분적으로 처리하거나, 특정 범위의 데이터를 효율적으로 선택하는 데 유용합니다.
# loc을 사용한 슬라이싱
df.loc[0:2, 'age':'fare'] # 0~2번째 행과 'age'부터 'fare'까지의 열 선택
# iloc을 사용한 슬라이싱
df.iloc[0:3, 1:4] # 0~2번째 행과 1~3번째 열 선택
3. 조건부 필터링
- df.loc는 조건을 지정하여 데이터를 필터링할 때 매우 유용합니다. 라벨과 조건을 결합하여 필요한 데이터만 선택할 수 있습니다.
# 나이가 30 이상인 모든 행 선택
df.loc[df['age'] >= 30]
4. 데이터 수정과 할당
- df.loc와 df.iloc를 사용하여 특정 데이터 위치에 값을 할당하거나 수정할 수 있습니다. 이는 특정 행이나 열을 대상으로 값을 변경하거나 계산 결과를 저장할 때 매우 유용합니다.
# loc을 사용한 데이터 수정
df.loc[0, 'age'] = 25 # 첫 번째 행의 'age' 열 값을 25로 변경
# iloc을 사용한 데이터 수정
df.iloc[0, 1] = 50 # 첫 번째 행의 두 번째 열 값을 50으로 변경
loc vs 체인 인덱싱 비교
3,4 번을 조합하면 아래와 같이 특정 조건을 만족하는 값들을 변경할 수 있습니다.
df.loc[df['age'] >= 30, 'age'] = 25
그런데, 사실 이와 똑같은 결과가 나오는 다른 방식의 코드도 존재한다. 바로 아래와 같은 체인인덱싱 코드입니다.
df[df['age'] >= 30['age'] = 25
둘 사이에는 어떤 코드가 더 좋을까? 정답은 loc를 사용하는 것입니다. 이유는 메모리 효율성이 좋아서 연산 속도가 더 빠르고, SettingWithCopyWarning가 발생하지 않기 때문입니다. 이는 pandas에서 데이터프레임의 복사본이 아닌 원본을 수정하려고 할 때 경고를 표시하는 것입니다. 쉽게 말해서 df.copy()로 복사본을 만들었다면, df에 아무리 위 코드를 적용해도 적용이 되지 않는 문제입니다. 물론 df.copy()를 사용하지 않을 거라면 문제없이 사용할 순 있습니다. 자세한 내용은 이 문서를 참고하세요.
5. 명확한 오류 메시지와 데이터 무결성 유지
- 잘못된 라벨이나 인덱스에 접근할 경우, loc과 iloc은 명확한 오류 메시지를 제공하여 디버깅을 쉽게 할 수 있습니다. 또한, 데이터프레임의 무결성을 유지하며, 인덱싱 오류로 인해 발생할 수 있는 문제를 예방합니다.
6. 일관된 데이터 접근 방법
- df.loc와 df.iloc를 사용하면 코드가 일관되고 명확해지며, 데이터 접근 방식을 통일할 수 있습니다. 특히, 다양한 유형의 데이터(예: 문자열 라벨, 정수 인덱스 등)를 다룰 때 유용합니다.
loc, iloc 실습
그럼 실습을 진행해보겠습니다. 우선 타이타닉 데이터셋을 불러와줍니다.
import seaborn as sns
df = sns.load_dataset('titanic')
df.head()
1. loc
아래와 같이 첫 번째 행, 'sex'열을 선택하게 되면, female 값이 선택됩니다.
df.loc[1, 'sex']
# 결과 : 'female'
df.loc[1]을 하면 index가 1인 전체 행을 불러오게 됩니다.
df.loc[1]
: 표시는 전체를 불러오겠다는 뜻입니다. 아래와 같이 작성하면, 'age'열의 전체 행을 불러오게 됩니다.
df.loc[:,'age']
여러 행과 여러 열을 동시에 선택하는 것도 가능합니다.
df.loc[1:3,['sex','age']]

특정 행을 지정해서 가져올 수도 있습니다.
df.loc[[1,2,5],'age']
특정 조건을 만족하는 행을 선택해서 가져올 수도 있습니다.
df.loc[df['age'] >= 30, 'age']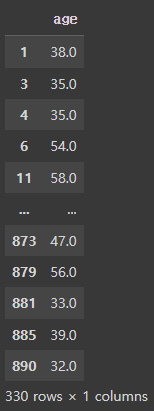
2. iloc
iloc는 인덱스 숫자로 접근하는 방식이기 때문에 '열'의 경우에도 숫자로 접근해야합니다.
df.iloc[1, 2]
# 결과 : 'female'
그래서 iloc에서는 df.iloc[df['age'] >= 30, 'age'] 이런식으로 '행'의 위치에 조건을 붙여서 사용할 수 없다. 대신 iloc는 -1 인덱스를 사용할 수 있습니다.
아래와 같이 df.iloc[-1]을 하면 마지막 행을 선택해서 가져오게 됩니다.
df.iloc[-1]
열도 마찬가지로 -1을 하면 가장 마지막 열을 선택합니다.
df.iloc[-1,-1]
# 결과 : 'True'
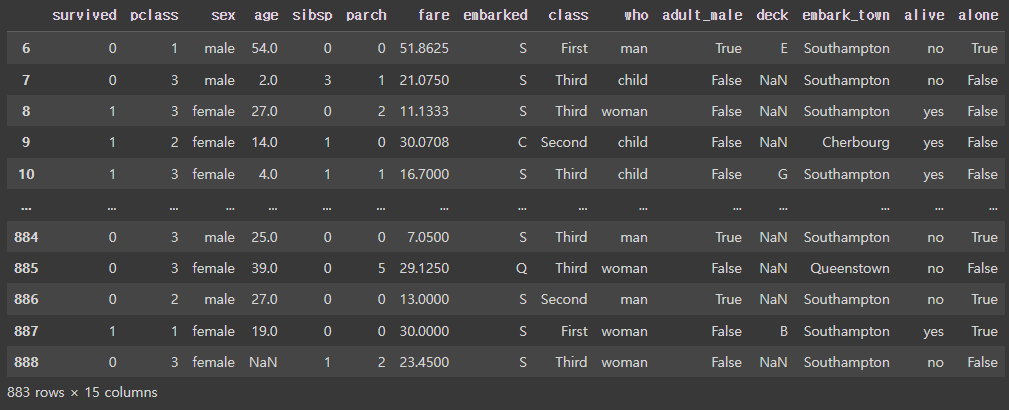
그렇다면 이렇게 코드를 작성하면 어떤 결과가 나올까요?
df.iloc[6:-2]
답은 전체 열에 대한 7번째 행(=index : 6)부터 뒤에서 두번째 행까지를 선택해서 가져오게 됩니다.
과제
과제 1: 기본 데이터 선택과 필터링
- 데이터 준비: pandas의 내장 데이터셋 중 하나를 로드합니다. 예를 들어, seaborn 라이브러리의 titanic 데이터셋을 사용합니다.
- 행과 열 선택:
- loc을 사용하여 특정 행과 열을 선택합니다. 예를 들어, age가 30 이상인 행의 age와 fare 열을 선택합니다.
- iloc을 사용하여 데이터프레임의 첫 번째~5행과 첫 번째~3열을 선택합니다.
- 조건부 필터링:
- loc을 사용하여 age가 30 이상인 사람들 중 sex가 'female'인 사람들의 name과 age를 선택합니다.
- iloc을 사용하여 마지막 5행을 선택하고, 열 2부터 4까지의 데이터를 추출합니다.
과제 2: 데이터 수정과 조건부 업데이트
- 데이터 수정:
- loc을 사용하여 age가 40 이상인 모든 사람의 fare 값을 100으로 변경합니다.
- iloc을 사용하여 데이터프레임의 첫 10행 중 age 열의 값을 20으로 변경합니다.
- NaN 값 처리:
- loc을 사용하여 age 열의 NaN 값을 평균 나이로 대체합니다.
- iloc을 사용하여 특정 행의 NaN 값을 0으로 대체합니다.
과제 3: 복잡한 조건과 슬라이싱
- 복잡한 조건:
- loc을 사용하여 age가 20 이상 40 이하인 사람들 중 class가 'First'인 사람들의 name, age, fare를 선택합니다.
- iloc을 사용하여 age가 25 이상인 사람들의 데이터 중 열의 위치를 사용하여 name과 fare를 선택합니다.
- 슬라이싱:
- loc을 사용하여 데이터프레임의 10번째부터 20번째 행과 age, fare 열을 선택합니다.
- iloc을 사용하여 전체 데이터프레임에서 10행에서 20행까지, 그리고 2열에서 5열까지 선택합니다.
과제 4: 데이터 요약과 집계
- 행과 열 요약:
- loc을 사용하여 age가 30 이상인 사람들의 데이터에서 age의 평균과 표준편차를 계산합니다.
- iloc을 사용하여 데이터프레임의 첫 10행의 age 열의 총합을 계산합니다.
- 데이터 요약:
- loc을 사용하여 class가 'Third'인 사람들 중 fare의 평균을 계산합니다.
- iloc을 사용하여 데이터프레임의 첫 5행에서 fare 열의 최대값을 찾습니다.
과제 5: 데이터 정렬과 조건부 선택
- 데이터 정렬:
- loc을 사용하여 age 열을 기준으로 오름차순으로 정렬하고, 상위 5개의 행을 선택합니다.
- iloc을 사용하여 fare 열을 기준으로 내림차순으로 정렬하고, 첫 10개의 행을 선택합니다.
- 조건부 선택과 정렬:
- loc을 사용하여 age가 25 이상인 사람들을 선택하고, fare 열을 기준으로 내림차순으로 정렬하여 상위 5개의 행을 선택합니다.
- iloc을 사용하여 age가 35 이하인 사람들의 데이터를 선택하고, age 열을 기준으로 오름차순으로 정렬하여 상위 10개의 행을 선택합니다.
정답
과제 1: 기본 데이터 선택과 필터링
1. 데이터 준비:
import seaborn as sns
import pandas as pd
df = sns.load_dataset('titanic')
2. 행과 열 선택:
- loc을 사용하여 age가 30 이상인 행의 age와 fare 열을 선택합니다.
df.loc[df['age'] >= 30, ['age', 'fare']]- iloc을 사용하여 데이터프레임의 첫 번째~5행과 첫 번째~3열을 선택합니다.
df.iloc[:5, :3]
3. 조건부 필터링:
- loc을 사용하여 age가 30 이상인 사람들 중 sex가 'female'인 사람들의 name과 age를 선택합니다.
df.loc[(df['age'] >= 30) & (df['sex'] == 'female'), ['name', 'age']]- iloc을 사용하여 마지막 5행을 선택하고, 열 2부터 4까지의 데이터를 추출합니다.
df.iloc[-5:, 2:5]
과제 2: 데이터 수정과 조건부 업데이트
1. 데이터 수정:
- loc을 사용하여 age가 40 이상인 모든 사람의 fare 값을 100으로 변경합니다.
df.loc[df['age'] >= 40, 'fare'] = 100- iloc을 사용하여 데이터프레임의 첫 10행 중 age 열의 값을 20으로 변경합니다.
df.iloc[:10, df.columns.get_loc('age')] = 20
2. NaN 값 처리:
- loc을 사용하여 age 열의 NaN 값을 평균 나이로 대체합니다.
# NaN 값을 제외한 평균 나이 계산
mean_age = df['age'].mean()
# NaN 값을 평균 나이로 대체
df.loc[df['age'].isna(), 'age'] = mean_age
과제 3: 복잡한 조건과 슬라이싱
1. 복잡한 조건:
- loc을 사용하여 age가 20 이상 40 이하인 사람들 중 class가 'First'인 사람들의 name, age, fare를 선택합니다.
df.loc[(df['age'] >= 20) & (df['age'] <= 40) & (df['class'] == 'First'), ['name', 'age', 'fare']]- iloc을 사용하여 age가 25 이상인 사람들의 데이터 중 열의 위치를 사용하여 name과 fare를 선택합니다.
df.iloc[df[df['age'] >= 25].index, [df.columns.get_loc('name'), df.columns.get_loc('fare')]]
2. 슬라이싱:
- loc을 사용하여 데이터프레임의 10번째부터 20번째 행과 age, fare 열을 선택합니다.
df.loc[10:20, ['age', 'fare']]- iloc을 사용하여 전체 데이터프레임에서 10행에서 20행까지, 그리고 2열에서 5열까지 선택합니다.
df.iloc[10:20, 2:6]
과제 4: 데이터 요약과 집계
1. 행과 열 요약:
- loc을 사용하여 age가 30 이상인 사람들의 데이터에서 age의 평균과 표준편차를 계산합니다.
df.loc[df['age'] >= 30, 'age'].agg(['mean', 'std'])- iloc을 사용하여 데이터프레임의 첫 10행의 age 열의 총합을 계산합니다.
df.iloc[:10, df.columns.get_loc('age')].sum()
2. 데이터 요약:
- loc을 사용하여 class가 'Third'인 사람들 중 fare의 평균을 계산합니다.
df.loc[df['class'] == 'Third', 'fare'].mean()- iloc을 사용하여 데이터프레임의 첫 5행에서 fare 열의 최대값을 찾습니다.
df.iloc[:5, df.columns.get_loc('fare')].max()
과제 5: 데이터 정렬과 조건부 선택
1. 데이터 정렬:
- loc을 사용하여 age 열을 기준으로 오름차순으로 정렬하고, 상위 5개의 행을 선택합니다.
df.loc[df['age'].sort_values().index[:5]]- iloc을 사용하여 fare 열을 기준으로 내림차순으로 정렬하고, 첫 10개의 행을 선택합니다.
df.iloc[df['fare'].sort_values(ascending=False).index[:10]]
2. 조건부 선택과 정렬:
- loc을 사용하여 age가 25 이상인 사람들을 선택하고, fare 열을 기준으로 내림차순으로 정렬하여 상위 5개의 행을 선택합니다.
df.loc[df['age'] >= 25].sort_values(by='fare', ascending=False)- iloc을 사용하여 age가 35 이하인 사람들의 데이터를 선택하고, age 열을 기준으로 오름차순으로 정렬하여 상위 10개의 행을 선택합니다.
df.iloc[df[df['age'] <= 35].sort_values(by='age').index[:10]]
참고
'파이썬' 카테고리의 다른 글
| Python 개발환경 설정 (3) | 2024.09.11 |
|---|---|
| [Python] Pandas : Dataframe 함수 - merge() (0) | 2024.08.16 |
| [Python] Pandas : Dataframe 함수 - groupby() 사용법 (1) | 2024.07.27 |
| [Python] Pandas : Dataframe 함수 - reset_index() (0) | 2024.06.09 |
| [Python] Pandas : Dataframe 함수 - replace() (1) | 2024.06.09 |



댓글