데이터 분석이나 시각화 작업을 하다 보면 데이터를 변환해야 할 때가 많습니다. 그중 가장 많이 사용하는 변환 중 하나가 데이터를 넓은 형식(wide format)에서 긴 형식(long format)으로 바꾸는 작업입니다. Pandas의 melt() 함수는 바로 이러한 변환을 쉽게 해주는 도구입니다. 이번 포스트에서는 melt() 함수의 기본 사용법부터 다양한 옵션을 살펴보겠습니다.
1. melt() 함수란?
melt() 함수는 넓은 형식의 데이터를 긴 형식으로 변환하는 함수입니다. 예를 들어, 여러 개의 열(column)로 구분된 데이터를 하나의 열로 병합하고, 병합된 값을 기준으로 데이터 프레임을 재구성할 수 있습니다. 이를 통해 시각화나 분석에 더 적합한 형태로 데이터를 변형할 수 있습니다.
넓은 형식 vs 긴 형식
- 넓은 형식(wide format): 각 변수별로 별도의 열이 존재하는 데이터 형식.
- 긴 형식(long format): 모든 변수 값을 하나의 열로 모아서 정리된 데이터 형식.
2. melt() 함수의 기본 문법
pandas.melt(frame, id_vars=None, value_vars=None, var_name=None, value_name='value', col_level=None, ignore_index=True)
- frame: 변환할 데이터프레임.
- id_vars: 변하지 않는 열. 이 열들은 그대로 유지됩니다.
- value_vars: 녹일(병합할) 열. 이 열들이 긴 형식의 새로운 열로 변환됩니다.
- var_name: 새로운 열에 들어갈 변수명. 기본값은 'variable'.
- value_name: 새로운 열에 들어갈 값의 열 이름. 기본값은 'value'.
- ignore_index: 기존 인덱스를 유지할지 여부. 기본값은 True.
3. melt() 함수 사용 예시
(1) 기본적인 사용 예시
먼저 melt() 함수를 사용하여 넓은 데이터를 긴 형식으로 변환하는 기본적인 예시를 살펴보겠습니다.
import pandas as pd
# 예시 데이터 생성
df = pd.DataFrame({
'Name': ['Alice', 'Bob', 'Charlie'],
'Math': [85, 90, 78],
'English': [88, 79, 85],
'Science': [92, 85, 89]
})
# melt 함수로 데이터를 긴 형식으로 변환
pd.melt(df, id_vars='Name', value_vars=['Math', 'English', 'Science'])
| Name | Math | English | Science |
| Alice | 85 | 88 | 92 |
| Bob | 90 | 79 | 85 |
| Charlie | 78 | 85 | 89 |

- id_vars='Name': Name 열은 그대로 유지됩니다.
- value_vars=['Math', 'English', 'Science']: Math, English, Science 열들이 긴 형식으로 변환됩니다.
- 기본적으로 녹여진 열들은 variable이라는 새 열에 들어가고, 해당 값은 value라는 열에 배치됩니다.
(2) var_name과 value_name 옵션 사용
기본적으로 melt() 함수는 새로 생성된 열의 이름을 variable과 value로 설정합니다. 하지만 var_name과 value_name 옵션을 사용하여 이 열들의 이름을 커스터마이즈할 수 있습니다.
# 열 이름 변경
pd.melt(df, id_vars='Name', value_vars=['Math', 'English', 'Science'], var_name='Subject', value_name='Score')
- var_name='Subject': variable 대신 Subject라는 이름으로 새 열을 설정.
- value_name='Score': value 대신 Score라는 이름으로 값을 설정.
(3) value_vars 없이 사용하기
만약 value_vars 옵션을 지정하지 않으면, id_vars로 설정된 열을 제외한 모든 열이 자동으로 병합됩니다.
# value_vars 생략
pd.melt(df, id_vars='Name')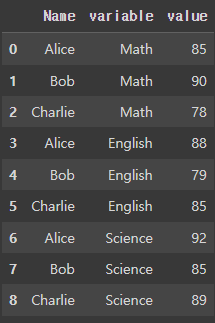
- id_vars='Name': Name을 제외한 모든 열(Math, English, Science)이 자동으로 병합됩니다.
(4) 여러 개의 id_vars 사용
id_vars에는 여러 개의 열을 지정할 수 있습니다. 이를 통해 변하지 않는 열을 다중으로 설정하고, 나머지 열들을 긴 형식으로 변환할 수 있습니다.
# 예시 데이터 생성
df_multi_id = pd.DataFrame({
'Name': ['Alice', 'Bob', 'Charlie'],
'Class': ['Math101', 'Math101', 'Math101'],
'Midterm': [85, 90, 78],
'Final': [88, 79, 85]
})
# 여러 개의 id_vars 사용
pd.melt(df_multi_id, id_vars=['Name', 'Class'], value_vars=['Midterm', 'Final'])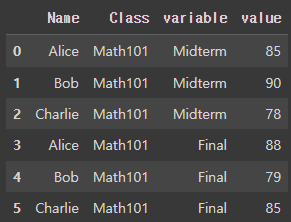
- id_vars=['Name', 'Class']: Name과 Class 열이 그대로 유지되며, Midterm과 Final 열이 긴 형식으로 변환됩니다.
(5) ignore_index=False: 기존 인덱스 유지
기본적으로 melt() 함수는 인덱스를 재설정합니다. 하지만 ignore_index=False를 설정하면 기존 인덱스를 유지할 수 있습니다.
# 인덱스 유지
pd.melt(df, id_vars='Name', value_vars=['Math', 'English', 'Science'], ignore_index=False)
- 기존 인덱스(0, 1, 2)가 그대로 유지되며, 각 열의 값들이 변환된 데이터에 반영됩니다.
4. melt() 함수 사용 사례 및 실전 예시
(1) 넓은 형식에서 긴 형식으로 변환하여 시각화에 활용
데이터 시각화 도구는 긴 형식의 데이터를 요구하는 경우가 많습니다. melt()를 사용하면 넓은 형식의 데이터를 쉽게 긴 형식으로 변환하여 시각화할 수 있습니다.
예시: 학생 성적 데이터 시각화
import seaborn as sns
import matplotlib.pyplot as plt
# 예시 데이터
df = pd.DataFrame({
'Name': ['Alice', 'Bob', 'Charlie'],
'Math': [85, 90, 78],
'English': [88, 79, 85],
'Science': [92, 85, 89]
})
# 데이터를 긴 형식으로 변환
melted_df = pd.melt(df, id_vars='Name', value_vars=['Math', 'English', 'Science'], var_name='Subject', value_name='Score')
# Seaborn을 사용한 시각화
sns.barplot(x='Name', y='Score', hue='Subject', data=melted_df)
plt.title("Subject grades for each student")
plt.show()
이 예제에서는 melt()로 데이터를 변환한 후 Seaborn 라이브러리로 시각화를 합니다. 각 학생의 과목별 성적을 한눈에 볼 수 있도록 막대 그래프로 표현합니다.
(2) 데이터 전처리에서의 활용
데이터 분석에서 melt()는 주로 데이터 전처리 과정에서 활용됩니다. 넓은 형식의 데이터를 긴 형식으로 변환한 후 추가적인 분석을 수행하거나 머신러닝 모델에 넣을 준비를 할 수 있습니다. 특히 반복되는 변수명이 여러 열에 걸쳐 나타나는 경우 melt()를 사용해 데이터를 효율적으로 변형할 수 있습니다.
예시: 매출 데이터 전처리
# 예시 매출 데이터
sales_data = pd.DataFrame({
'Product': ['Product A', 'Product B'],
'2023_Q1': [200, 150],
'2023_Q2': [210, 160],
'2023_Q3': [205, 155]
})
# melt() 함수로 긴 형식으로 변환
pd.melt(sales_data, id_vars='Product', var_name='Quarter', value_name='Sales')
이제 각 제품의 분기별 매출을 분석하거나 예측 모델에 적용할 수 있습니다. melt()를 통해 데이터가 깔끔하게 정리되면 분석 작업이 훨씬 더 수월해집니다.
5. melt()와 반대되는 pivot() 함수
melt()는 넓은 데이터를 긴 형식으로 변환하는 함수입니다. 반대로, 긴 형식의 데이터를 다시 넓은 형식으로 변환하려면 Pandas의 pivot() 또는 pivot_table() 함수를 사용할 수 있습니다. 예를 들어, 앞서 사용한 melt() 함수로 변환한 데이터를 다시 원래의 넓은 형식으로 돌리고 싶다면 pivot() 함수를 사용하면 됩니다.
melt()로 변환한 데이터를 다시 넓은 형식으로 복구하기
# 예시 데이터
df = pd.DataFrame({
'Name': ['Alice', 'Bob', 'Charlie'],
'Math': [85, 90, 78],
'English': [88, 79, 85],
'Science': [92, 85, 89]
})
# 데이터를 긴 형식으로 변환
melted_df = pd.melt(df, id_vars='Name', value_vars=['Math', 'English', 'Science'], var_name='Subject', value_name='Score')
# melt로 변환한 데이터를 다시 넓은 형식으로 복구
melted_df.pivot(index='Name', columns='Subject', values='Score')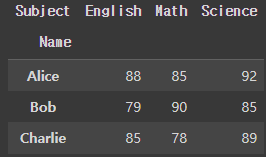
pivot() 함수는 melt()의 반대 작업을 수행합니다. 데이터를 다시 넓은 형식으로 변환하고, 각 행과 열의 기준에 맞춰 값을 채워넣습니다. pivot() 함수에 대한 자세한 설명은 이 글을 참고해보세요.
6. 결론
Pandas의 melt() 함수는 데이터를 긴 형식으로 변환하는 데 매우 유용하며, 특히 데이터 시각화와 전처리 단계에서 자주 사용됩니다. 데이터를 분석하거나 시각화할 때, 넓은 형식보다는 긴 형식이 더 적합한 경우가 많기 때문에 melt() 함수는 그 과정을 매우 간단하게 만들어 줍니다.
다양한 옵션을 활용해 데이터의 변형 과정을 유연하게 제어할 수 있으며, 특히 id_vars, value_vars, var_name, value_name 등을 통해 원하는 데이터 구조를 쉽게 만들 수 있습니다. 데이터를 정리하고 분석 준비를 할 때, melt() 함수 기능을 적극 활용해보세요!
'파이썬' 카테고리의 다른 글
| 파이썬 퀀트투자(2): 한국거래소 업종 분류 현황 크롤링 (1) | 2024.10.09 |
|---|---|
| 파이썬 퀀트투자(1): 최근 영업일 기준 데이터 크롤링 (7) | 2024.10.09 |
| [Python] Pandas : Dataframe 함수 - pivot() vs pivot_table() (1) | 2024.09.29 |
| [Python] Pandas : Dataframe 함수 - concat() (0) | 2024.09.29 |
| Python 개발환경 설정 (3) | 2024.09.11 |




댓글