이 글에서는 Python의 Matplotlib 라이브러리를 사용하여 다양한 막대 그래프를 그리는 방법을 상세하게 설명합니다. 기본 막대 그래프부터 수평 막대, 그룹별 그래프, 에러바, 누적 및 100% 누적 바 차트까지 다룹니다. 각 예시에는 필요한 속성과 코드 설명이 포함되어 있습니다.
목차
1. Matplotlib 기본 막대 그래프 그리기
먼저 가장 기본적인 Matplotlib 라이브러리의 막대 그래프를 그릴 건데요. plt.bar() 함수를 사용합니다.
import matplotlib.pyplot as plt
# 데이터
labels = ['A', 'B', 'C', 'D']
values = [3, 7, 1, 9]
# 그래프 그리기
plt.bar(labels, values)
# 제목과 레이블 추가
plt.title('Matplotlib Bar Graph')
plt.xlabel('Labels')
plt.ylabel('Values')
# 그래프 보이기
plt.show()labels는 X축에 들어갈 카테고리들이고, values는 그 카테고리에 해당하는 값입니다. 여기서는 간단하게 4개의 레이블('A', 'B', 'C', 'D')과 그에 해당하는 값들([3, 7, 1, 9])을 사용했습니다.
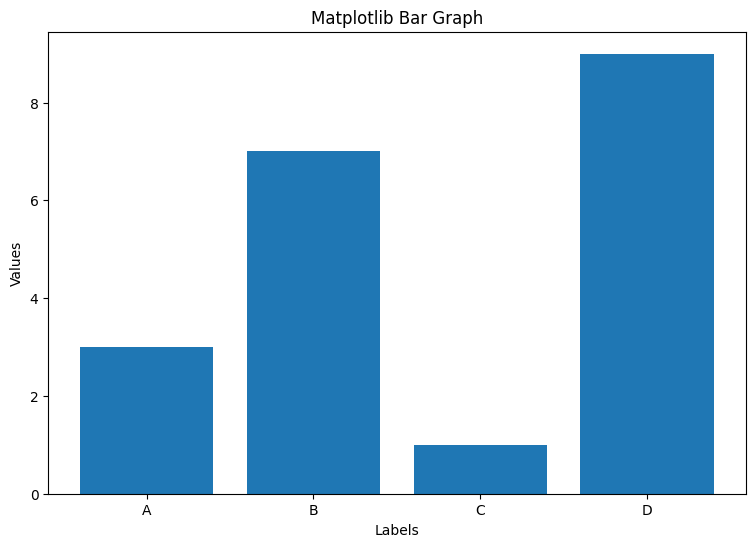
2. 수평 막대 그래프 그리기
이번에는 plt.barh()를 사용해 수평 막대 그래프를 그려볼 거예요. 여기서 h는 'horizontal'의 약자입니다. 기본 막대 그래프와 거의 똑같은데, 막대가 수평으로 나타납니다. X축과 y축 변수는 위에서 사용했던걸 그대로 사용했습니다.
plt.barh(labels, values)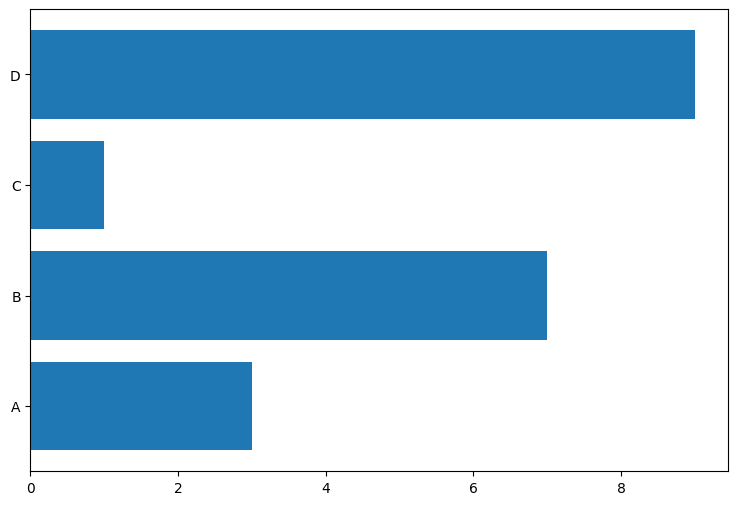
3. 여러 그룹 데이터 비교하기
이제 조금 더 복잡한 데이터를 다룰 건데, 여러 그룹의 데이터를 같이 비교할 수 있게 그룹별로 데이터를 나눠서 그래프를 그려보겠습니다. 먼저 그룹별 데이터를 만들어보겠습니다.
import pandas as pd
# 데이터 프레임 생성
# 데이터 생성
data = {
'Labels': ['A', 'A', 'B', 'B', 'C', 'C', 'D', 'D'],
'Values': [3, 2, 7, 6, 9, 4, 5, 8],
'Group': ['Group 1', 'Group 2', 'Group 1', 'Group 2', 'Group 1', 'Group 2', 'Group 1', 'Group 2']
}
df = pd.DataFrame(data)Group1과 Group2에 각각 A, B, C, D Lables값이 생성되었습니다. 여기서 plt.subplot()을 사용하면 여러 개의 그래프를 하나의 플롯에 나타낼 수 있어요.
count = 1
plt.figure(figsize=(9,6))
for i in df['Group'].unique(): # Group 1, Group 2
df_group = df[df['Group'] == i]
plt.subplot(2,1,count) # 2행, 1열, 1번째
plt.bar(df_group['Labels'], df_group['Values'])
count += 1
plt.show()df['Group'].unique()로 고유한 그룹 이름을 찾고, for문에 넣으면 'Group 1'과 'Group 2'가 들어가서 총 2번 반복합니다. 이를 df_group이라는 변수에 할당하면, Group 1일 때의 전체 테이블, Group 2일 때의 전체 테이블이 각각 저장됩니다. plt.subplot(2,1,1) 이런 식으로 숫자가 들어가면, 2행, 1열의 1번째 위치에 그래프를 그리겠다는 뜻입니다. count는 1부터 시작해 2까지 올라가니 서브플롯이 그룹별로 총 2개가 생성되겠죠?
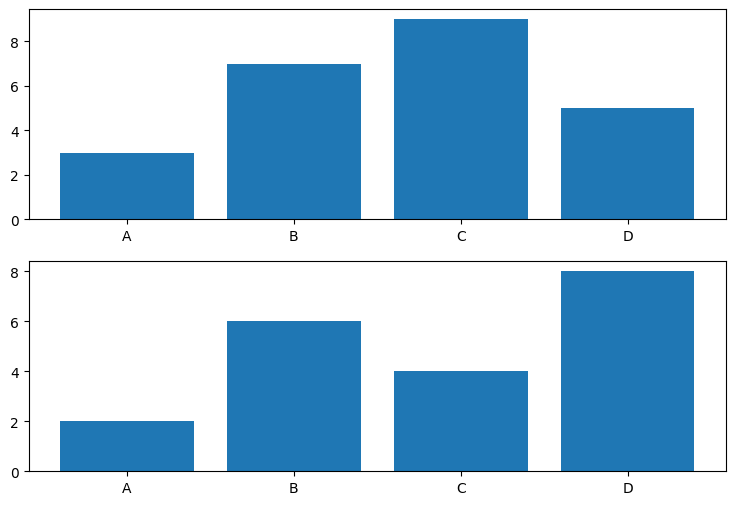
4. 여러 그룹 하나의 그래프에 담기
다음은 두 그룹의 데이터를 하나의 그래프에 모두 담아 그리는 방법입니다. X 위치를 약간 조정하여 두 그룹의 막대가 겹치지 않게 하는 것이 중요해요. 이렇게 하면 하나의 레이블에 대한 두 그룹의 값을 한눈에 비교할 수 있습니다. 여기서는 2가지 방법을 소개할 거예요.
1) x 위치를 조정해서 설정하기(많이 사용하지 않음)
이 방법은 사실 많이 사용하지 않습니다. seaborn의 'hue'라는 속성을 사용하면, 훨씬 쉽게 구현이 가능하기 때문이죠. 이런 방법도 있구나 하고 넘어가시면 됩니다 :)
# Correctly setting the 'value1' and 'value2'
value1 = df[df['Group'] == 'Group 1']['Values'].values
value2 = df[df['Group'] == 'Group 2']['Values'].values
# Unique labels
labels = df['Labels'].unique()
# X coordinates
x = np.arange(len(labels)) array([0, 1, 2, 3])
# Draw the bars for Group 1 and Group 2
plt.bar(x - 0.2, value1, width=0.4, color='blue', label='Group 1')
plt.bar(x + 0.2, value2, width=0.4, color='green', label='Group 2')
# Add labels and title
plt.xlabel('Labels')
plt.ylabel('Values')
plt.title('Two Bar Graphs in One Plot')
plt.xticks(ticks=x, labels=labels)
plt.legend()
# Show the plot
plt.show()value1, value2라는 변수에 그룹별로 데이터를 나눠서 그에 해당하는 vlaues값을 할당합니다. labels의 유니크 값을 할당합니다. x축에 라벨 유니크 값 개수만큼의 배열 'array([0, 1, 2, 3])'을 저장합니다. plt.bar() 함수 안에 width 속성을 활용해서 bar의 넓이를 0.4로 설정합니다. 이 상태에서 첫 번째 그룹의 x축 위치에 0.2를 빼고, 두 번째 그룹의 x축 위치에 0.2를 더하면 두 그래프의 위치가 서로 0.4만큼 차이 나기 때문에 아래 그래프처럼 딱 간격이 맞게 2개의 그룹으로 그래프가 나뉘게 됩니다. 이때, plt.xticks에 ticks(x축 위치)와 labels를 설정해 줘야 x축이 A, B, C, D으로 변환됩니다.
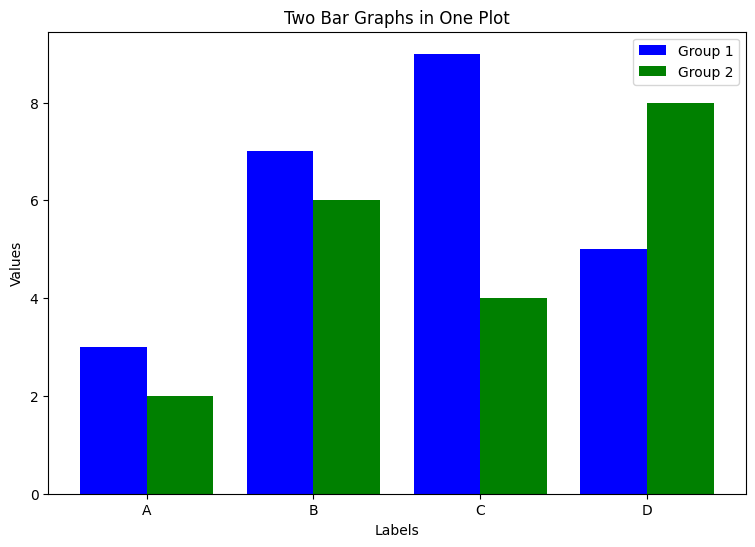
2) 피벗 테이블을 활용해서 설정하기
1번보다 훨씬 간단한 방법입니다. 판다스의 데이터 프레임은 엑셀처럼 피벗테이블을 만들 수 있는 기능을 제공합니다.
# 집계함수 사용 불가능, 형태만 변경
df_pivot = df.pivot(columns='Group', index='Labels', values='Values')
df_pivot.plot(kind='bar')columns에 Group을, index에 Lables를, values에 Values를 넣고 피벗테이블을 만들면 아래와 같은 테이블이 만들어집니다. 이렇게 만들어진 피벗테이블을 가지고, df_pivot.plot() 함수만 적용하면 그래프가 바로 만들어집니다. 하지만 기본 그래프는 lineplot이기 때문에 kind='bar'라고 입력하여 막대그래프로 만들어주어야 합니다.
| Group 1 | Group 2 | |
| A | 3 | 2 |
| B | 7 | 6 |
| C | 9 | 4 |
| D | 5 | 8 |
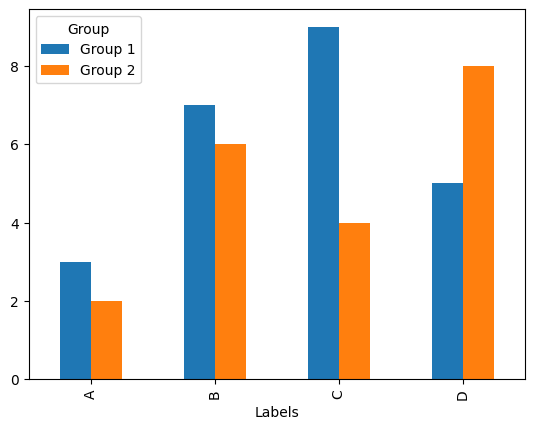
df.plot() 형태의 함수는 Pandas DataFrame 객체의 메서드입니다. 이 메서드는 내부적으로 Matplotlib 라이브러리를 사용하므로, Matplotlib의 기능과 유사하게 작동하는 것이죠. 그래프의 종류로는 'bar', 'line', 'barh', 'hist', 'box', 'kde', 'area', 'pie' 등이 있습니다.
5. errorbar 그리기(평균, 표준편차)
통계 데이터를 다룰 때, 평균만 보는 것보다 표준편차를 함께 보면 더 유용합니다. plt.bar() 함수의 yerr 옵션을 사용하면 이런 에러바를 추가할 수 있어요.
df_mean = df.groupby('Labels').mean()
df_std = df.groupby('Labels').std()
plt.bar(df_mean.index, df_mean['Values'], yerr=df_std['Values'], capsize=3)Lables를 기준으로 그룹으로 묶고, 평균값과 표준편차 값을 계산하여 각각 df_mean, df_std에 데이터프레임 형태로 담습니다. 그러면 아래와 같은 테이블이 각각 생성됩니다.(왼쪽 df_mean, 오른쪽 df_std)
| Lables | Values | Lables | Values |
| A | 2.5 | A | 0.707107 |
| B | 6.5 | B | 0.707107 |
| C | 6.5 | C | 3.535534 |
| D | 6.5 | D | 2.121320 |
x축에 df_mean의 라벨을, y축에 df_mean의 Values값을, yerr에 df_std의 Values값을 넣고 그래프를 그리면 아래와 같이 평균과 표준편차를 나타내는 errorbar 그래프가 만들어집니다. 이때, capsize를 통해서 에러바의 상단과 하단에 수평방향의 막대 모양을 추가할 수 있습니다.
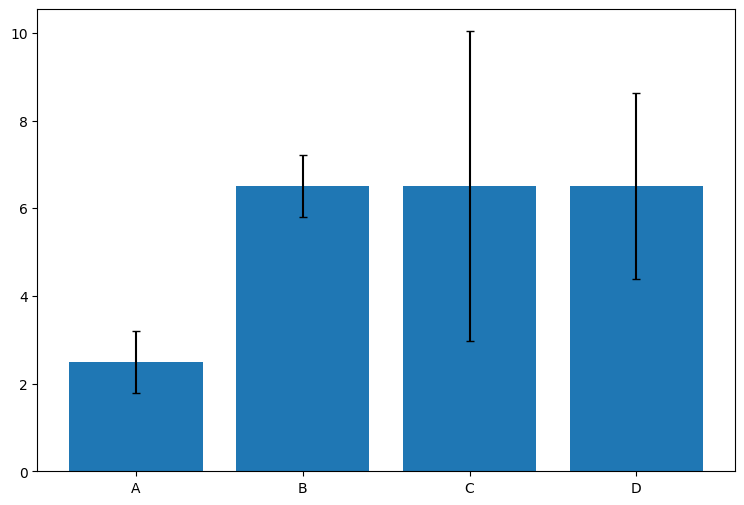
6. 누적 바 차트 그리기
다음은 누적 바 차트입니다. 누적 바 차트는 여러 그룹의 값을 하나의 막대로 쌓아서 보여줍니다. 이는 각 그룹이 전체에서 차지하는 비중을 한눈에 볼 수 있게 해 줍니다. 누적 바 차트를 그리기 위해서는 위에서 피벗테이블을 만들었던 것처럼 비슷한 형태로 데이터프레임을 바꿔주어야 합니다. 여기서는 df.groupby()를 사용하겠습니다. 피벗테이블과 차이는 집계함수를 적용할 수 있다는 점입니다. 예를 들어 Lables가 A이고, Group이 Group 1인 Values 값이 2개 이상인 경우엔 아래와 같은 형태로 피벗테이블을 만드는 것이 불가능하지만, groupby는 집계함수를 통해 sum, mean 등으로 계산하여 하나의 값으로 합칠 수 있죠.
# 집계함수 사용 가능
df_group = df.groupby(['Labels','Group'])['Values'].mean().unstack('Group')df.groupby(['Labels','Group'])['Values'].mean()은 Lables와 Group을 기준으로 중복 값을 제거하고 Values의 평균값을 계산한다는 뜻입니다. unstack()에 'Group'을 입력하면 Group을 열로 지정하겠다는 뜻입니다.
| Labels | Group 1 | Group 2 |
| A | 3 | 2 |
| B | 7 | 6 |
| C | 9 | 4 |
| D | 5 | 8 |
1) bottom 속성으로 그리기
기본 막대 그래프를 2번 그리는 형식과 비슷합니다. 한 가지 다른 점은 bottom 속성을 사용하다는 것인데, bottom에 첫 번째 그린 그래프의 y값을 할당하면, 그 값을 0으로 인식하고 그래프를 그리겠다는 뜻입니다.
plt.bar(df_group.index, df_group['Group 1'])
plt.bar(df_group.index, df_group['Group 2'], bottom=df_group['Group 1'])
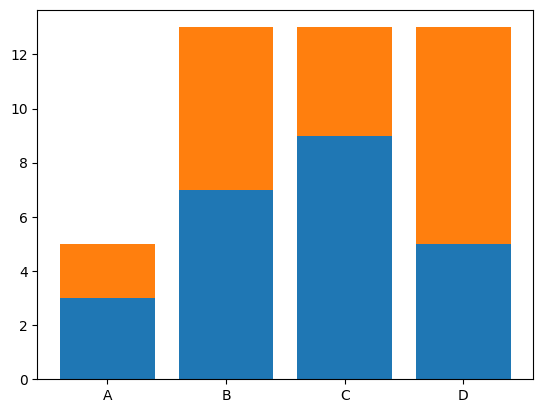
2) stacked 속성으로 그리기
피벗테이블로 그래프를 그렸던 것처럼 판다스 데이터 프레임의 plot 함수를 사용해서도 누적 바 차트를 그릴 수 있습니다. stacked=True 속성을 입력하기만 하면 쉽게 누적 바 차트가 그려집니다.
df_group.plot(kind='bar', stacked=True)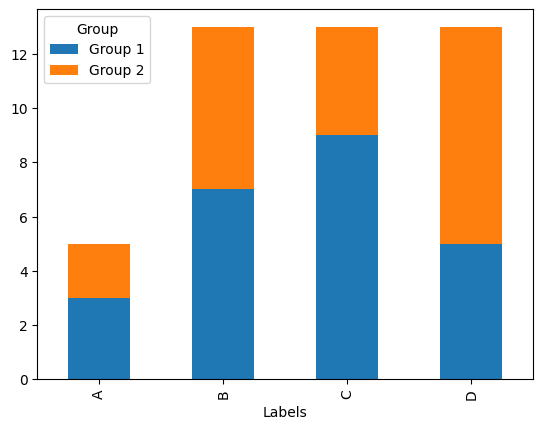
7. 100% 누적바 그리기
100% 누적 바 차트는 전체를 100%로 보고, 각 그룹이 차지하는 비율을 보여줍니다. 이를 통해 상대적인 크기 비교가 한눈에 가능합니다. 각 그룹의 값을 전체 값으로 나눠 비율을 계산한 다음, 이 비율을 바 차트로 그려야 합니다. 전체 값으로 나누려면 Total 값이 있어야 하기 때문에 아래와 같이 'Total' 컬럼을 추가해 줍니다.
# Create a true copy of df_group to keep it unchanged
df_group_total = df_group.copy()
# Add the 'Total' column
df_group_total['Total'] = df_group_total.sum(axis=1)| Labels | Group 1 | Group 2 | Total |
| A | 3 | 2 | 5 |
| B | 7 | 6 | 13 |
| C | 9 | 4 | 13 |
| D | 5 | 8 | 13 |
다음은 Group 1, Group 2로 나눠서 각각 Total값으로 나누고, 100을 곱해서 계산한 비율값을 다시 할당합니다.
# Normalize each group to sum up to 100%
for col in ['Group 1', 'Group 2']:
# Normalize each group to sum up to 100%
df_group_total[col] = df_group_total[col] / df_group_total['Total'] * 100
df_group_100 = df_group_total.drop('Total', axis=1)
df_group_100.plot(kind='bar', stacked=True)
# Add labels and title
plt.xlabel('Labels')
plt.ylabel('Percentage (%)')
plt.title('100% Stacked Bar Chart')
plt.legend()
# Show the plot
plt.show()
'Total' 컬럼을 다시 삭제하고, stacked 속성을 활용해서 그래프를 그리면 100% 누적 바 차트가 완성됩니다!
8. 속성 요약
- x: x축 위치 (배열 혹은 스칼라)
- height: 막대의 높이 (배열 혹은 스칼라)
- width: 막대의 너비 (기본값은 0.8)
- color: 막대의 색상
- edgecolor: 막대의 테두리 색상
- linewidth: 테두리 라인의 너비
- align: 막대가 x 좌표에 어떻게 정렬될지 ('edge' 또는 'center', 기본값은 'center')
- label: 범례에 표시될 라벨
- orientation: 막대가 수직 ('vertical') 인지 수평 ('horizontal') 인지
결론
여러 가지 막대 그래프를 그리는 방법을 알아봤는데요, 특히 누적 바 차트나 100% 누적 바 차트를 그릴 때는 matplotlib가 유용하게 사용됩니다. 반면 그룹별로 한 그래프에 나타낼 땐 seaborn으로 더 간단하게 그래프를 그릴 수 있죠. 하지만 이 2가지 라이브러리는 데이터가 어떻게 생겼느냐에 따라 활용할 수 있는 범위가 다르기 때문에 2개 다 충분히 익혀서 더 알맞은 라이브러리를 적절히 선택하여 사용하는 것이 중요합니다!
글을 다 읽어보신 분들을 위해 코드를 연습해 볼 수 있도록 코드를 깃허브에 첨부해 두었습니다. 다운로드해 가시면 제가 이 포스팅에서 사용했던 코드를 연습해 보실 수 있습니다! 또한, 그래프를 급하게 그려야 하는데, 직접 배워서 하기엔 시간이 부족하신 분들은 제가 크몽에서 시각화 외주 서비스를 진행하고 있으니 도움이 필요하시면 편하게 연락해 주세요! 여기까지 Matplotlib로 막대 그래프를 그리는 7가지 방법에 대해서 알아보았습니다 :)
함께보면 좋은 글
'시각화, 대시보드' 카테고리의 다른 글
| 앱시트 + 구글 스프레드시트로 개인용 앱 만들기 1시간 컷 (0) | 2023.11.06 |
|---|---|
| Seaborn 막대 그래프 7가지 종류 그리는 방법 (vs Matplotlib) (1) | 2023.10.27 |
| Matplotlib Subplot 활용해서 그래프 여러개 그리는 3가지 방법 (0) | 2023.10.12 |
| 데이터 시각화를 하는 이유, 좋은 시각화 핵심 법칙 (0) | 2023.10.11 |
| plt.legend 옵션으로 그래프 범례 모양 커스터마이즈하기 (0) | 2023.10.10 |




댓글