목차
1. 규제화(Regularization)란?
2. L1 penalty term
3. L2 penalty term
지난 시간에 기계학습 종류와 지도학습 중에서도 선형회귀 문제에 대해서 알아보았다.(참고글 - 기계학습(ML): 선형회귀 모델 학습 원리, 성능 평가 방법) 그중 성능 평가 단계에서 선형회귀 문제에 대한 성능평가를 할 수 있는 지표는 \(R^2\)가 있었고, 평가가 단계에서 모형의 성능이 좋지 않은 경우 보통 과적합(Overfitiing) 문제라고 했다. 과적합이 일어나는 주된 이유는 첫 번째로, 사용하는 모형에 존재하는 파라미터의 수가 너무 많은 경우가 있었고 두 번째로, 학습을 통해서 도출된 수학적 모형이 독립변수의 값의 변화에 너무 민감하게 반응하는 경우가 있었다. 그리고 이를 해결할 수 있는 방법으로는 규제화(Regularization) 방법이 있었고, 규제화 방법의 종류에는 L1 Penalty term과 L2 Penalty term이 있었다.

그럼 이제, 위 마인드맵에서 빨간색으로 표시되어있는 규제화에 대해 알아보고, 다음 시간에는 선형 회귀 모델에서 성능평가를 할 때 사용하는 \(R^2\) 지표에 대해서 알아보겠다.
1. 규제화(Regularization)란?
규제화란, 지도학습 모델의 성능 평가 단계에서 Overfitting(과적합)이 일어나는 경우에 이를 해결하기 위해서 사용하는 방법이다. 과적합이 일어나는 이유는 크게 2가지이다.
1. 모형이 너무 복잡한 경우, 즉 모형의 파라미터의 갯수가 너무 많은 경우이다.
2. 학습을 통해서 도출된 수학적 모형이 독립변수의 값의 변화에 너무 민감하게 반응하는 경우, 즉 독립변수에 붙어있는 파라미터의 값이 너무 큰 경우이다.
이러한 경우, 우리는 규제화(Regularization)를 통해서 과적합을 해결할 수 있다. 규제화는 기존의 비용함수에 penalty term을 더해서 새로운 비용함수로 사용하는 방법이다.
$$ E(b)_{new}= E(b)_{org} + penalty $$
예를 들어보자. \( y = b_1X \) 이라는 수학적 모형이 있다. 여기서 \(b_1\) 파라미터의 최적값을 찾기 위해서는 비용함수 mse를 사용해야 한다. 아래와 같은 표가 있을 때, 비용함수를 통해서 \(b_1\)을 구해보자.
| 사원 | 경력(X) | 연봉(y) |
| A | 1 | 2 |
| B | 2 | 6 |


이렇게 계산했을 때, 아래로 비용함수 E와 파라미터\(b_1\)의 관계는 아래로 볼록한 그래프로 그려진다.(위 그래프 참고) 여기에 penalty 항을 추가적으로 더해주어서 새로운 비용함수를 만드는 것이 바로, 규제화이다. 위 그래프에서 \(b_1\)의 최적값은 정규방정식으로 통해 미분해서 계산하면, 14/5가 되지만, 아래 수식처럼 penalty항 추가되면, \(b_1\)의 최적값 또한 달라지게 된다.
$$ E(b_1)_{new} = \frac{5}{2}b_{1}^2 - 14b_1 + 20 + penalty $$
그렇다면 Penalty 항의 식은 어떻게 생겼을까? Penalty는 L1페널티 항과 L2페널티 항 이렇게 두 가지 종류가 있다. L1페널티 항과 L2페널티 항에 대해서 이해하려면, 기본적으로 벡터의 길이에 대해서 알아야한다. 이를 나타내는 개념이 \(norm\)이다.
벡터는 간단하게 이야기 하면, 여러 개의 숫자들로 구성이 되어있는 어떤 것이다. 예를 들어 \(a = (1,2,3)\)은 3개의 숫자로 구성이 된 하나의 벡터이고, 각각의 숫자를 원소라고 한다.(벡터에 대한 글이 아니기 때문에 자세한 설명은 넘어가겠다.) \(norm\) 중에서 가장 많이 사용되는 게 \(L^p - norm\)이라는 지표이다. 이 지표의 식은 다음과 같다.
$$ L^p - norm = ||x||_p = (\sum_{i=1}^{k}|x_i|^p)^{1/p} $$
\(L1 - norm\)은 p에 1을, \(L2 - norm\)은 p에 2를 대입해준다.
$$ L1 - norm = |x_1| + |x_2| + ... + |x_k| $$
$$ L2 - norm = \sqrt{|x_1|^2 + |x_2|^2 + ... + |x_k|^2} $$
위 식을 보면, \(L1 - norm\)은 x의 절댓값을 전부 더해준 값이라는 걸 알 수 있다. L1 norm을 이용한 페널티 항이 L1 Penalty term이다. 또한, \(L1 - norm\)은 x의 제곱을 해준 값을 전부 더한 후에 전체를 루트를 씌운 값이다. L2 norm을 이용한 페널티 항이 L2 Penalty term이다. 각각의 항에 대해 더 자세히 알아보자.
2. L1 Penalty term
위에서 \(L1 - norm\)과 \(L2 - norm\) 식을 살펴보았다. 이 중에서 \(L1 - norm\)를 이용한 패널티 항이 L1 Penalty term이라고 했다. 규제화 식을 다시 보자.
$$ E(b)_{new}= E(b)_{org} + penalty $$
L1 Penalty term을 사용한다면, 위식에서 penalty 항에 \(λ||b||_1\)를 대입해 주면 된다. 이 값은 아래와 같이 표현할 수 있다. 즉, 각각의 파라미터들에 절댓값을 취하고, 이걸 전부 더한 후, 람다를 곱한 값이 된다.
$$ penalty = λ||b||_1 = λ(|b_1| + |b_2| + ... + |b_k|) $$
여기에서 \(||b||_1\)는 벡터의 \(L1 - norm\)을 뜻한다. 람다(λ)는 하이퍼파라이미터로, 페널티 강도를 의미한다. 람다도 경사하강법에서 사용하는 에타처럼 사람이 직접 설정해주어야 한다. 일반적으로 0보다 큰 값을 사용한다. 람다의 크기를 키우면, 키울수록 페널티항이 커지기 때문에 기존의 파라미터 절댓값이 더 많이 줄어들게 된다. 위 예시에 사용했던 식에 대입해 보자.
$$ E(b_1)_{new} = \frac{5}{2}b_{1}^2 - 14b_1 + 20 + λ|b_1|$$
여기서 람다를 1로 설정하고, 기울기가 0인 값을 구하기 위해 미분을 하면, \(5b_1 -13\)이 된다. 페널티 항을 더하지 않은 상태에서 미분을 했다면, \(5b_1 -14\)이다. 각각의 기울기가 0이 되는 \(b_1\) 값을 찾으면, L1패널티 항을 더한 비용함수에서의 \(b_1\)은 13/5가 되고, 원래의 비용함수에서의 \(b_1\)은 14/5이다. 즉, 패널티 항을 더함으로써 새로운 \(b_1\)의 절댓값이 줄어들었다.
기존의 파라미터 절댓값이 더 많이 줄어들게 된다는 건 무슨 뜻일까? 특정 독립변수에 대한 종속변수의 변화의 민감도가 줄어들게 된다는 뜻이다. 예를 들어 종속변수(y)가 연봉이고, 독립변수가 경력(X1)과 몸무게(X2)가 있다면 모델은 다음과 같을 것이다.
ŷ = b0 + b1X1 + b2X2
이 모델에서 b2값이 지나치게 높다면, 경력보다 몸무게가 바뀌는 정도에 따라 종속변수인 연봉이 민감하게 변화하는 것이다. 현실적으로 생각해 봐도 말이 안 된다. 이럴 때, 페널티 항을 더해줌으로써 기존의 파라미터 절댓값을 줄여줄 수 있다. 파라미터가 b1 하나만 있다고 가정하고 L1 패널티 항을 그래프로 그리면 다음과 같이 그려진다.
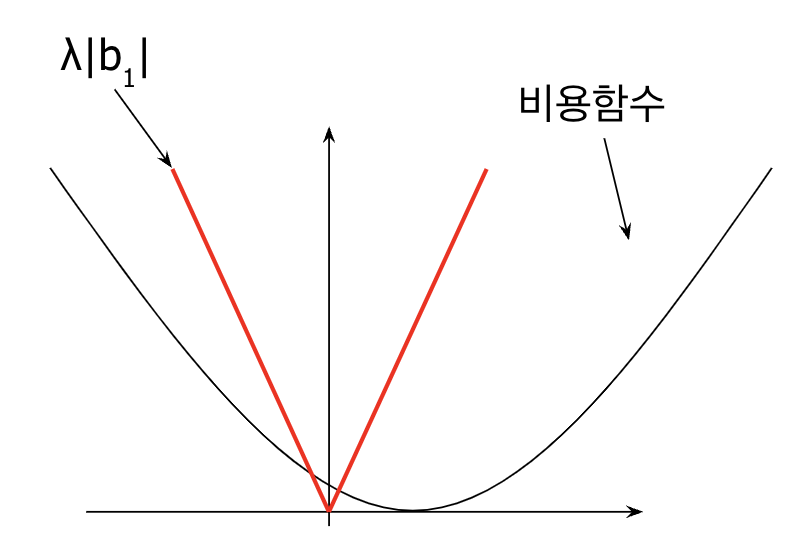
여기서 x축은 파라미터 \(b_1\)이고, y축은 비용함수 E이다. 즉, \(λ|b_1|\)은 위 빨간 선처럼 V자 형태를 띠는 그래프로 그려지고, 이때 람다의 값의 변화에 따라 기울기가 달라진다. 람다의 값이 높을수록, 뾰족한 V자 형태가 된다. 이제 위 두 그래프인 기존 비용함수(검정선) L1페널티 항(빨간 선)을 더해서 \(E(b)_{new}\)을 만들어 보자.
$$ E(b_1)_{new} = \frac{5}{2}b_{1}^2 - 14b_1 + 20 + λ|b_1| $$
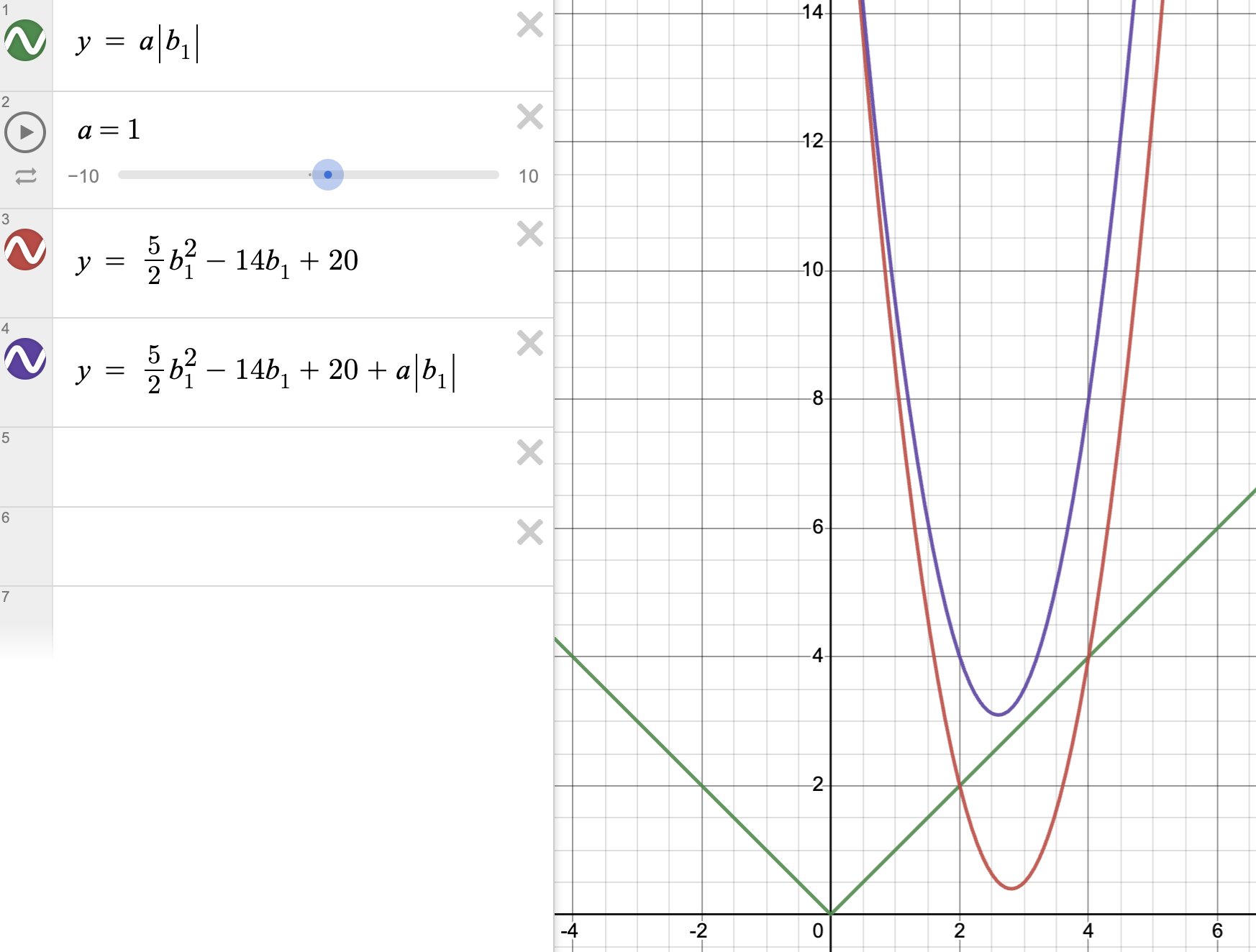
위 그래프와 같이 두 개의 그래프를 더하면, 보라색 그래프가 만들어진다. 기존의 비용함수인 빨간 그래프의 \(b_1\)의 최적값이 14/5였고, 초록색 선인 L1 페널티 항을 더해서 나온 보라색 그래프의 최적값이 13/5였다. 그래프상으로 확인해봐도 파라미터의 절대값이 작아졌다는 걸 알 수 있다. 그러면 위 그래프에서 람다값을 높이면 어떤 일이 일어날까?
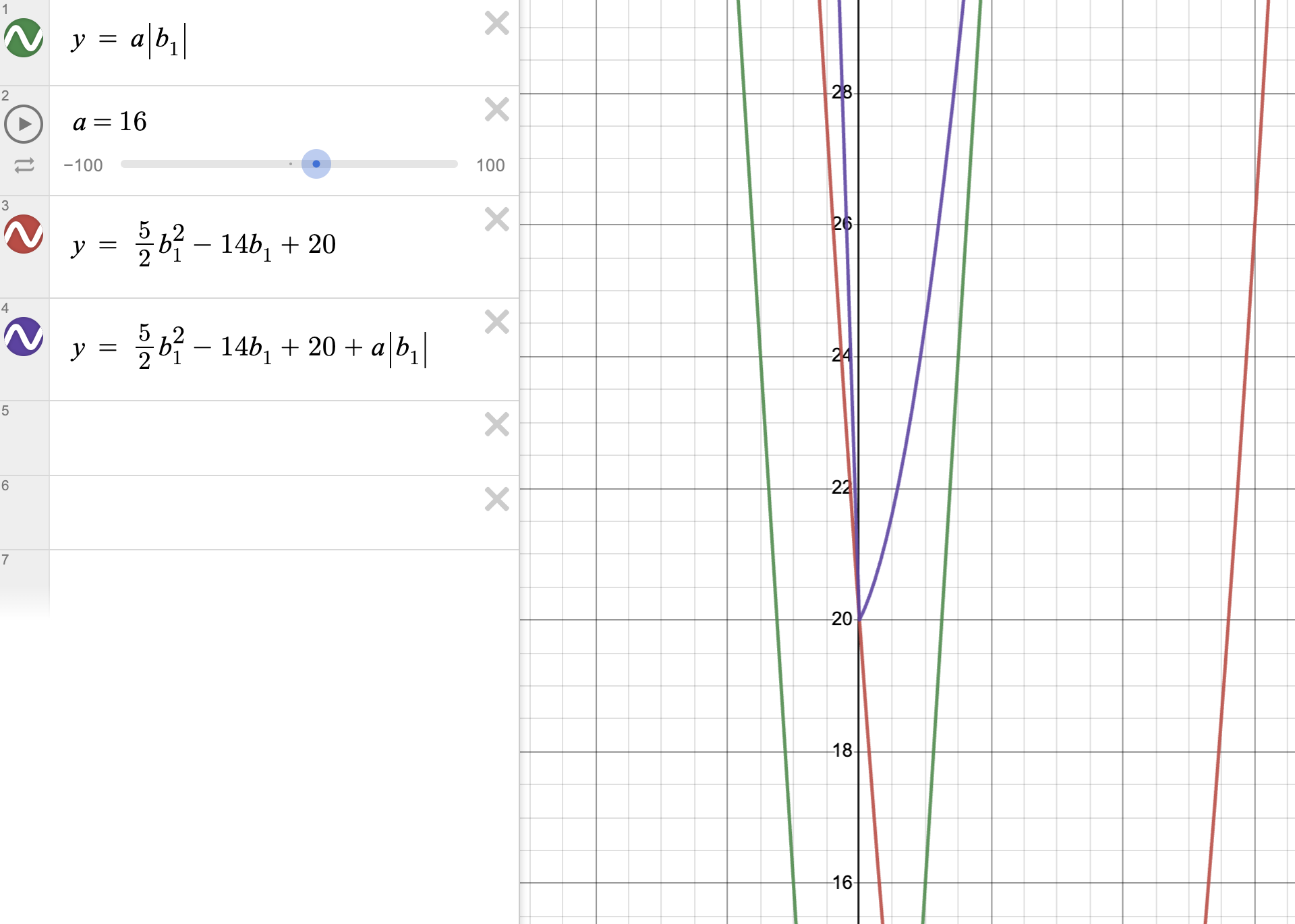
L1 패널티 항의 특징은 람다의 값을 일정 값 이상으로 높이면, 비용함수의 최적값이 0까지도 줄어들 수 있다는 점이다.(위 그래프 보라색 선 확인) 이 뜻은 모델의 민감도뿐만 아니라, 복잡도까지도 줄일 수 있다는 뜻이고, 복잡도를 줄인다는 것은 과적합(Overfitiing)이 일어나는 확률을 줄일 수 있다는 뜻이다. 즉, 모델의 성능을 높일 수 있다는 것이다.
3. L2 Penalty term
그럼 이번엔 \(L2 - norm\)를 이용한 페널티 항인 L2 Penalty term에 대해서 알아보자. \(L2 - norm\)은 아래와 같은 형태를 가지고 있었다.
$$ L2 - norm = ||x||_2 = \sqrt{|x_1|^2 + |x_2|^2 + ... + |x_k|^2} $$
L2 Penalty term을 식으로 표현하면, \(λ||b||_2^2\)이다. 즉, \(L2 - norm\)에 제곱을 취한 값에 람다를 곱한 값이다. 식으로 표현하면 다음과 같다. 루트와 제곱이 상쇄되어, 각 파라미터의 제곱 값을 더해서 람다로 곱한 값이 된다.
$$ penalty = λ||b||_2^2 = λ({b_1}^2 + {b_2}^2 + ... + {b_k}^2) $$
파라미터가 b1 하나만 있다면, 아래와 L2 penalty term은 아래와 같이 그려진다. L1 penalty term과 마찬가지로, 람다 값이 높아지면, 그래프가 더 뾰족한 모양이 된다.
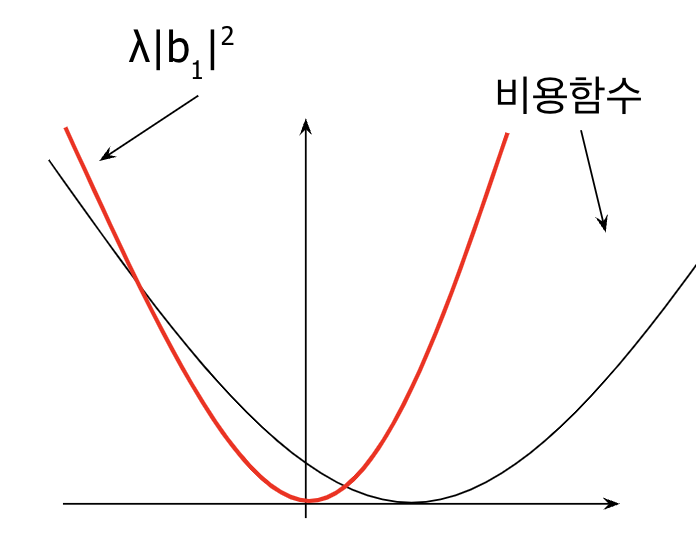
L1 penalty term에서 사용했던 식을 이용해서 똑같이 그래프를 그려보자.
$$ E(b_1)_{new} = \frac{5}{2}b_{1}^2 - 14b_1 + 20 + λ{b_1}^2 $$
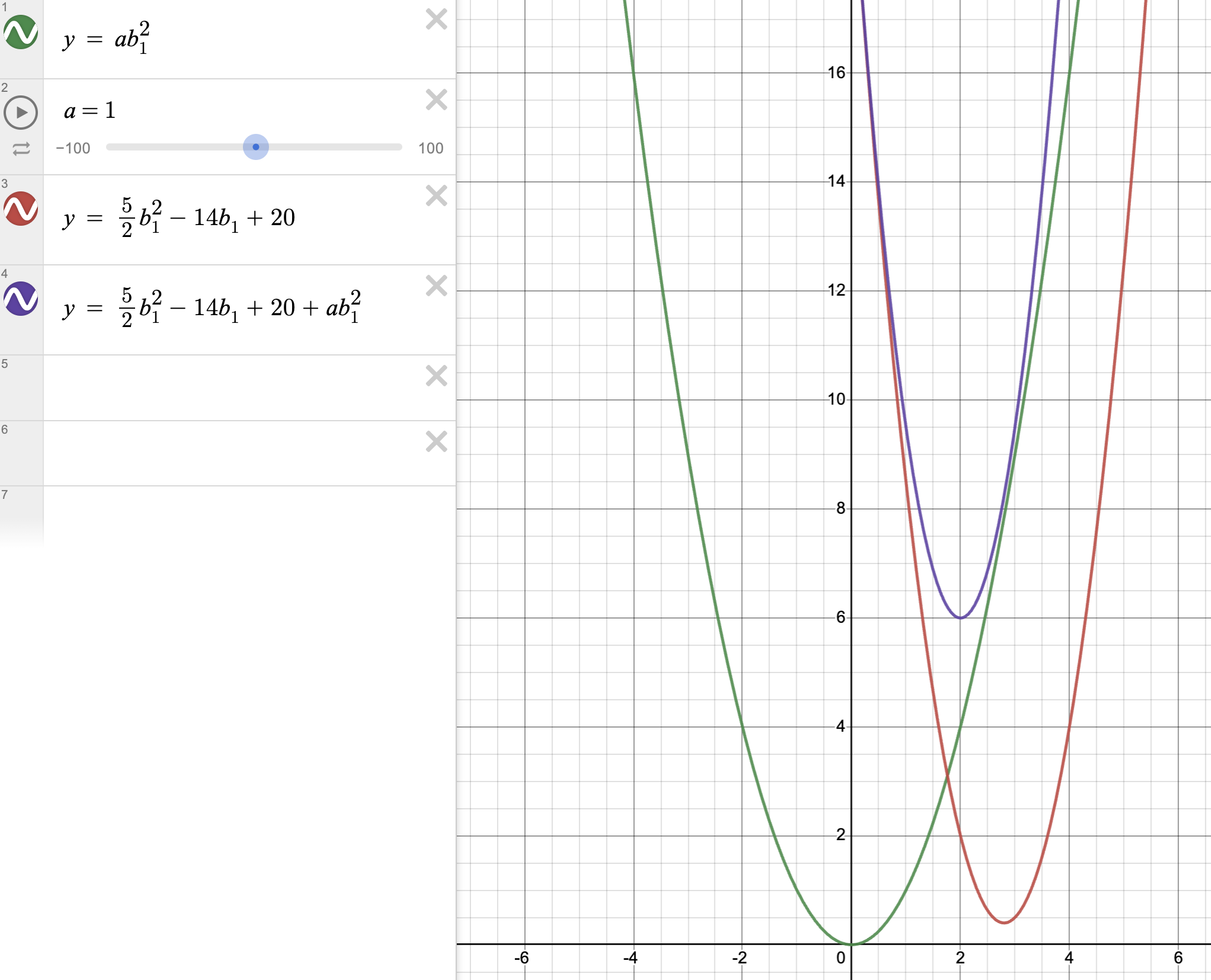
보라색 선이 기존의 비용함수와 L2 penalty term을 더한 그래프이다. L1 penalty term보다 람다 값에 더 민감하게 파라미터 \(b_1\)의 최적값이 줄어드는 걸 볼 수 있다.(13/5였던 것에 비해, 지금은 1/2이다.) 하지만 일정 수준 이상으로 람다 값을 올리면 어떻게 될까? L1 penalty term과 똑같이 람다를 16까지 올려보겠다.
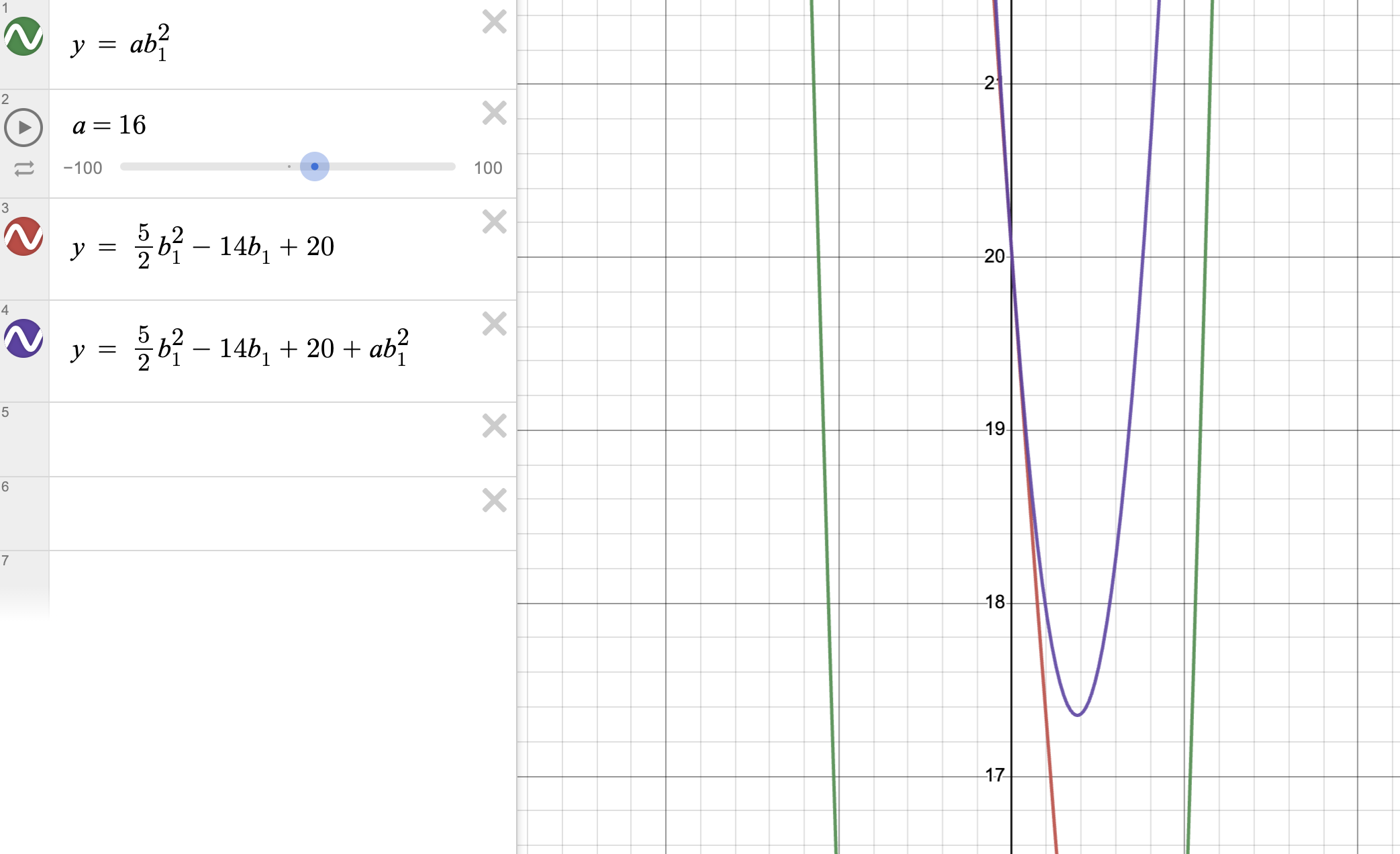
파라미터 \(b_1\)의 최적값이 0까지 줄어들지 않는다. L1 penalty term은 파라미터 \(b_1\)의 최적값이 0까지 줄어들었던 것과 비교가 되는 부분이다. L2 penalty term은 그래프가 아래로 볼록한 형태를 띠기 때문에 이러한 현상이 발생한다. 그냥 단순히 두 그래프의 y축을 더해보면 왜 이러한 현상이 일어나는지 알 수 있다.
즉, 모델의 민감도뿐만 아니라, 복잡도까지 줄이기 위해서는 L1 penalty term을 사용해야 한다. 또한, 람다의 값이 크면 클수록, 페널티 항을 더한 새로운 비용함수의 값이 더 크게 줄어들게 된다.(L1 penalty term은 0까지도 줄어든다.) L1과 L2 중에 어떤 걸 사용해야 하는지는 일 단 두 개 다 사용해 보고, 더 성능이 좋은 걸 선택하여 적용해야 된다.
'통계, AI' 카테고리의 다른 글
| 로지스틱 회귀 모형: 함수 개념 및 코딩 실습 (0) | 2023.05.29 |
|---|---|
| 회귀모델: 라쏘(Lasso), 릿지(Ridge), 엘라스틱 넷(ElasticNet) (0) | 2023.05.29 |
| 피처 스케일링: 표준화, min-max 정규화(feat. 파이썬) (1) | 2023.05.28 |
| \(R^2\)(선형회귀 모형 성능평가 지표) 계산 및 코드구현 방법 (0) | 2023.05.26 |
| 기계학습(ML): 선형회귀 모델 학습 원리, 성능 평가 방법 (4) | 2023.05.19 |




댓글