목차
1. 피처 스케일링(Feature scaling)이란?
2. 표준화(Standardzation)
2-1. 표준화 파이썬 구현
3. 민맥스 정규화(min-max normalization)
3-1. 정규화 파이썬 구현
저번시간에 성능평가 단계에서 선형회귀 모형의 성능 평가 지표인 \(R^2\)에 대해서 알아보았다. 이번시간에는 평가 단계에서 성능을 높이기 위해서 학습 단계 전에 미리 수행해야 하는 피처 스케일링에 대해서 알아보겠다.(해당 블로그에서 지금까지 다룬 부분의 전체 흐름은 아래 더 보기를 참고하자)
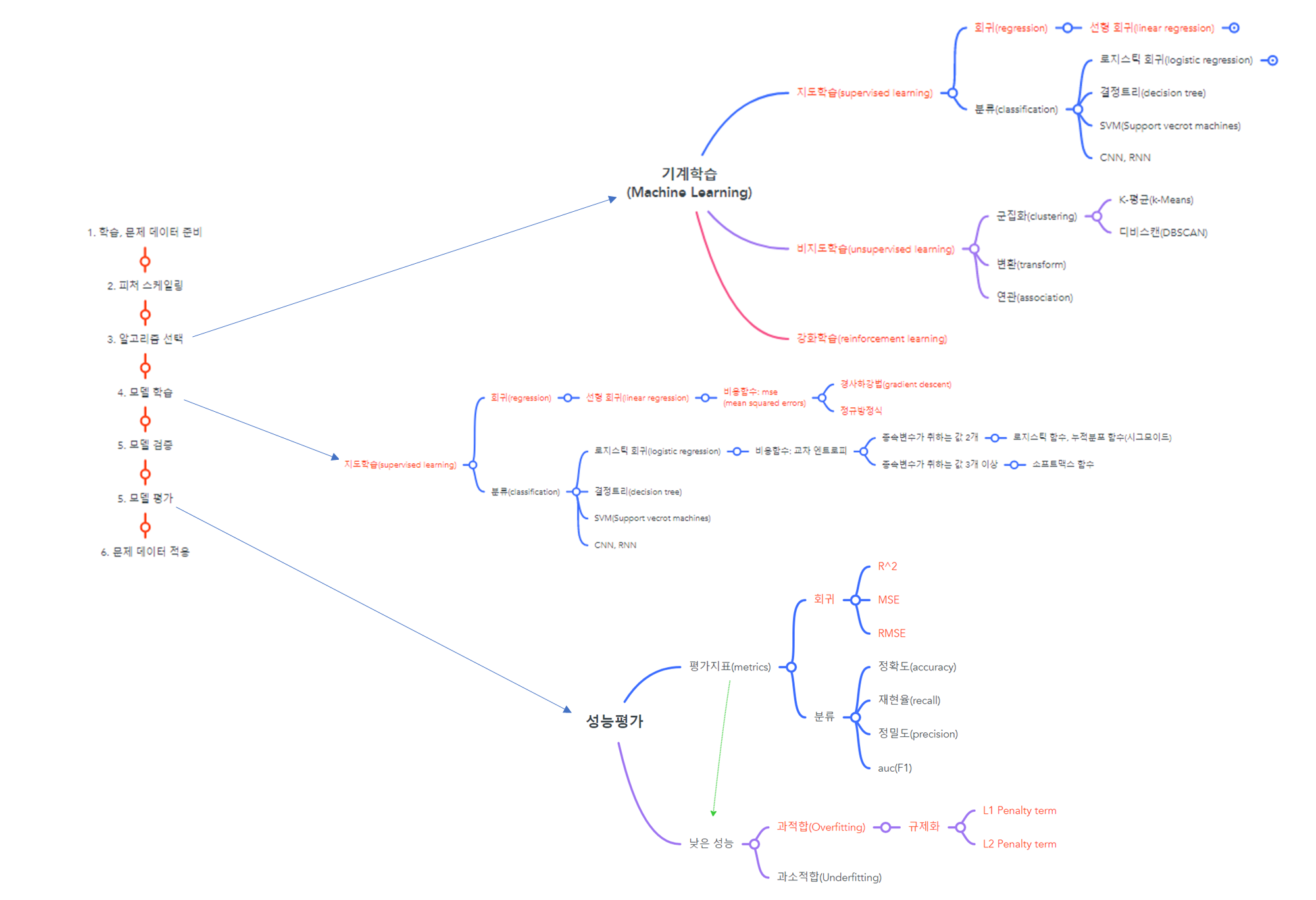
지난 시간까지 다루었던 부분 전체 흐름
(오른쪽 마인드맵의 빨간색으로 표시된 부분이 해당 블로그에서 다룬 부분)
1. 기계학습(ML): 선형회귀 모델 학습 원리, 성능 평가 방법
2. 규제화(Regularization): L1, L2 penalty term
3. \(R^2\)(선형회귀 모형 성능평가 지표) 계산 및 코드구현 방법
1. 피처 스케일링(Feature scaling)이란?
피처 스케일링이란, 독립변수(=feature)가 취하는 값의 범위를 맞춰주는 작업이다. 독립변수에 대해서만 수행하는 작업이기 때문에 종속변수(=target)에 대해서는 수행하면 안된다. 피처 스케일링의 주된 목적은 결국 모델의 성능을 높이기 위해서이다. 피처 스케일링을 수행하지 않으면 어떤 일이 발생할까?
예를들어 독립변수(=feature)가 경력(X1)과 나이(X2)가 있고, 종속변수(=target)가 연봉(y)이라고 해보자. 그러면 선형회귀 모델은 다음과 같을 것이다.
$$ y = b_0 + b_1X_1 + b_2X_2 $$
여기에서 만약, 특정 독립변수가(ex. X1) 분산이 크면, 비용함수(mse)가 최소가 되는 해당 독립변수(X1)에 대한 파라미터의 값(b1)이 실제 종속변수에 대한 설명력을 가지는 정도보다 더 큰 값이 나온다. 파라미터의 값이 크다는 건 종속변수에 대한 설명력이 그만큼 더 크다는 뜻이다. 그러면 과적합 현상이 일어나고, 과적합 현상이 일어나면 또다시, 규제화를 통해서 파라미터 값을 조정해주어야 한다. 이러한 현상을 막기 위해서 모델을 학습시키기 전에 독립변수를 미리 피처 스케일링을 수행해줘야 하는 것이다. 그렇게 되면 모델의 성능이 더 높아진다.
피처 스케일링은 언제 해야할까?
피처 스케일링은 학습 단계 전에 미리 수행해주어야 한다고 했다. 학습 단계에서 사용하는 데이터는 다시 학습 데이터와 평가 데이터로 나뉜다. 그러면, 피처 스케일링을 학습시키기 이전에 전체 데이터에 적용해야 할까? 그렇지 않다. 평가 데이터 같은 경우엔 사용되지 않은 데이터에 대해서 우리의 모형이 갖는 성능이 어떻게 되는지 파악하기 위해 사용하는 데이터이다. 전체 데이터에 대해서 피처스케일링을 한 후에 학습과 평가 데이터로 쪼개버리면, 학습데이터에 가지고 있는 정보가 평가에 대한 데이터에도 반영이 되어 버려서 더 이상 사용되지 않은 데이터라고 할 수 없게 된다. 즉, 전체데이터에 대해 피처스케일링을 하면, 평가 데이터로 정확한 성능 평가를 할 수가 없다.
그러면, 학습 데이터와 평가 데이터로 구분한 다음 각각 따로 피처스케일링 작업을 하면 될까? 역시 그렇지 않다. 따로따로 하게 되면 피처스케일하기 전에 동일했던 값이 피처스케일링을 한 후에는 학습데이터와 테스트 데이터가 서로 다른 값이 되어 버린다. 예를 들어, 학습데이터의 x값이 10이고, 평가 데이터의 x값도 10인 데이터가 있다면, 각각 따로 피처 스케일링 해버리면, 학습데이터의 x값은 5가 되고, 평가 데이터의 x값은 0이 되어버리는 상황이 생긴다. 종속변수 y값은 변화가 없는데도 말이다. 그래서 학습시키기 이전 단계에서 정답데이터를 학습과 평가 데이터로 나눈 후에 학습데이터에 적용시킨 피처 스케일링을 통해 평가데이터에도 적용을 하고 나서 학습을 진행해야 한다.
피처 스케일링을 하는 방법에는 크게 2가지가 있다. 표준화(Standardzation)와 민멕스 정규화(Min-max normalization)이다. 이에 대해 더 자세히 알아보자.
2. 표준화(Standardzation)
표준화는 해당변수를 표준화를 시켜서 사용하는 방법이다. 표준화 식은 다음과 같다.
$$ x_{new} = \frac{x-mean(X)}{SD(X)} = \frac{x-\bar{X}}{\sigma}$$
- \(mean(X) = \bar{X} \) : 평균
- \(SD(X) = \sigma\) : 표준편차
표준화는 독립변수들을 평균이 0이고, 분산이 1인 분포로 변경하는 피처 스케일링 방법이다. 학습데이터에서 도출된 평균과 표준편차를 이용해서 학습데이터에 대해서 표준화를 하고, 학습데이터의 평균값과 표준편차 값을 이용해서 평가데이터에 대해서도 표준화를 해야 한다.
ex) 학습 데이터 : 평균 = 5, 표준편차 = 1 → 평가데이터에도 동일하게 적용.
2-1. 표준화 파이썬 구현
이를 파이썬 코드로 구현해 보자. 먼저, 표준화 작업 이전에 학습데이터와 평가데이터로 분리시키는 작업을 먼저 수행한다.
import numpy as np
import pandas as pd
from sklearn.medel_selection import train_test_split
data = pd.read_csv("Scaler_data.csv")
X = data["feature"]
y = data["target"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=2)
데이터를 분리시켰다면, sklearn 모듈의 표준화 기능을 수행하는 StandardScaler() 클래스를 불러온다. 분리시킨 데이터에서 학습 데이터에 대해 fit_transform 함수를 적용하고, 테스트 데이터에 대해 transform() 함수를 적용한다.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_std = scaler.fit_transform(X_train)
X_test_std = scaler.transform(X_test)
fit_transform() 함수는 주어진 데이터셋을 분석하여 평균과 표준 편차를 추정한 후, 이를 적용하여 변환된 데이터셋을 반환한다. 즉, 학습과 변환을 한 번에 수행하는 함수이다. transform() 함수는 데이터에 대한 학습과정이 없으며, 이미 학습된 scaler를 새로운 데이터에 적용하는 데 사용된다. 이를 통해 이미 학습된 scaler을 재사용하거나, 다른 데이터셋에 동일한 변환을 적용할 수 있다.
평가 데이터로 정확한 성능 평가를 하기 위해서는 학습데이터에 표준화를 적용한 표준편차와 평균을 평가데이터에도 적용해야 한다고 했다. 그래서 위와 같이 학습 데이터에는 fit_transform() 함수를, 평가 데이터에는 transform() 함수를 적용하는 것이다.
3. 민맥스 정규화(Min-max normaliztion)
Min-max 정규화는 해당변수를 정규화시켜서 사용하는 방법이다. 식은 다음과 같다.
$$ x_{new} = \frac{x-min(X)}{max(X)-min(X)} $$
민맥스 정규화(Min-max noramlization)는 독립변수들의 값이 범위를 0~1 사이로 변경시켜 주는 피처 스케일링 방법이다. 예를 들어 x가 3이고, Min(X)가 0, Max(X)가 10이라면, 정규화 후에는 x값이 0.3이 된다. 표준화와 마찬가지로, 학습데이터에서 도출된 평균과 표준편차를 이용해서 학습데이터에 대해서 정규화를 하고, 정규화된 학습데이터의 값을 이용해서 평가데이터에 대해서도 정규화를 해야 한다.
3-1. 정규화 파이썬 구현
이를 파이썬 코드로 구현해 보자. 학습데이터와 평가데이터로 분리시키는 작업은 표준화와 동일하기 때문에 생략하고, 정규화 클래스를 먼저 불러와보겠다.
from sklearn.preprocessing import MinMaxScaler
scaler_minmax = MinMaxScaler()
클래스를 불러왔다면, 표준화와 마찬가지로 fit_transform() 함수와 transform() 함수를 동일하게 적용시켜 준다.
X_train_minmax = scaler_minmax.fit_transform(X_train)
X_test_minmax = scaler_minmax.transform(X_test)
여기까지 피처 스케일링이 무엇인지, 그리고 피처 스케일링의 방법인 표준화와 정규화에 대해서 알아보았다. 이렇게 표준화와 정규화를 두 개 다 모두 적용을 시켜보고, 모델의 성능이 더 좋은 걸 사용하면 된다.
정리
- 피처 스케일링? 독립변수들이 취하는 값의 범위를 맞춰주기 위해서 사용되는 방법. 독립변수에 대해서만 수행한다.
- 사용하는 이유: 독립변수의 분산을 맞춰줌으로써 모델의 성능을 높이기 위해.
- 주의할 점: 학습데이터에 먼저 적용시킨 피처스케일링 값을 평가데이터에도 동일하게 적용해야 한다.
- 피처 스케일링의 두 가지 방법: 표준화(Standardzation), 정규화(Min-max normalization)
'머신러닝,딥러닝 > ML 회귀분석(이상엽 교수님)' 카테고리의 다른 글
| 로지스틱 회귀 모형: 함수 개념 및 코딩 실습 (0) | 2023.05.29 |
|---|---|
| 회귀모델: 라쏘(Lasso), 릿지(Ridge), 엘라스틱 넷(ElasticNet) (0) | 2023.05.29 |
| \(R^2\)(선형회귀 모형 성능평가 지표) 계산 및 코드구현 방법 (0) | 2023.05.26 |
| 규제화(Regularization): L1, L2 penalty term (2) | 2023.05.23 |
| 기계학습(ML): 선형회귀 모델 학습 원리, 성능 평가 방법 (4) | 2023.05.19 |




댓글