목차
1. 원-핫 인코딩(One-Hot Encoding)
2. pd.get_dummies()
3. OneHotEncoder()
모델 학습을 위해서는 문자형태로 되어있는 범주형 데이터를 숫자형으로 바꿔 주어야 한다. 그런데, 문제가 하나 있다. 범주형 데이터를 숫자로 바꾸면 0,1,2,3,4 이런 식일 텐데, 이 숫자가 의미하는 바는 높다, 낮다 하는 수치가 아니라 범주를 나타내기 때문에 이 숫자를 회귀 분석에서 사용할 수 없다. 그러면 어떻게 해야 할까? 각각의 범주에 대한 컬럼을 따로 하나씩 더 만들어주고, 0과 1의 값만 갖도록 해야 한다. 예를 들어 '서울', '부산', '광주'라는 값을 가지는 범주형 데이터라면 서울, 부산, 광주에 대한 컬럼을 모두 하나씩 추가시켜 줄다음, 값이 서울이라면, 서울 컬럼만 1 나머지 컬럼은 0이 되게끔 세팅이 되어야 한다.
오늘은 이러한 예측 모델학습 단계 전에 작업해야 하는 범주형 데이터 인코딩하는 방법에 대해서 자세히 알아보겠다.
1. 원-핫 인코딩(One-Hot Encoding)
원-핫 인코딩(One-Hot Encoding)을 이해하려면, 우선 더미변수에 대해서 알아야 한다. 더미변수(dummy variable)는 독립변수를 0과 1로 변환한 변수를 뜻한다. 범주형 변수는 보통 문자열 데이터 형태를 가지고 있는데, 문자열 데이터는 기계 학습 알고리즘에 적용할 수 없다. 그렇기 때문에 주로 더비변수는 범주형 데이터를 처리하기 위해 사용된다. 원-핫 인코딩(One-Hot Encoding)은 범주형 데이터를 기계학습을 위해, 해당 범주에 속하는 경우 1로, 속하지 않는 경우 0으로 표시하게끔 변환하는 과정이다.
원-핫 인코딩의 방법에는 여러가지가 있다. pd.get_dummies(), OneHotEncoder(), LabelEncoder(), OdinalEncoder() 등 여러 가지 방법이 있다. 오늘은 가장 간단하게 구현이 가능한 pd.get_dummies()와 학습데이터와 평가데이터의 범주 수가 다를 때 사용하는 OneHotEncoder()에 대해서 먼저 알아보겠다.
2. pd.get_dummies()
판다스의 pd.get_dummies() 함수는 명목변수*만 0과 1로 원-핫 인코딩을 해준다. 어떤 의미인지 코딩을 해보면서 이해해 보자.
*명목변수: '남녀'같이 카테고리를 표현하는 변수로, 순위를 나타내지 않는 변수이다.
먼저 데이터 프레임을 만들어보겠다. 성별을 나타내는 gender, 자차 소유 여부를 나타내는 car, 가족 숫자를 나타내는 famliy_size, 업무용 휴대폰 소유 여부를 나타내는 work_phone이라는 독립변수를 만들었다. 그리고 이 독립변수로 예측하고 싶은 수입을 나타내는 income이라는 종속변수를 생성했다.
import pandas as pd
import numpy as np
## 데이터 생성
data = {
'gender' : ['male','female','male','male','female','male','male','female'],
'car' : ['N','Y','Y','Y','N','N','N','Y'],
'family_size' : [1,2,3,5,2,3,2,1,],
'work_phone' : [0,0,0,0,1,0,0,0],
'income' : [180,190,200,300,220,190,350,250]
}
df = pd.DataFrame(data)
이렇게 만든 데이터 프레임의 gender와 car는 문자열 데이터이다. 또한 gender, car, family_size, workphone은 모두 범주형 데이터이다. familiy_size 같은 경우엔 범주형 데이터라기 보단 연속형 데이터에 가깝다. 또한, work_phone 같은 경우엔 이미 0과 1의 두 가지 값을 가지며, 각각은 범주형 변수의 한 범주를 나타내고 있다. 그러므로 familiy_size와 work_phone를 제외한 나머지 독립변수에 대해서 pd.get_dummies() 함수를 통해 인코딩해줘야 한다. 그럼 함수를 사용해 보자.
첫 번째 인자에는 더미변수로 바꿔줄 데이터를 넣는다. 그다음 더미변수로 바꿔 줄 범주형 컬럼 이름을 넣어준다. 이때, columns을 따로 지정하지 않으면 문자열 데이터로 이루어진 컬럼들이 자동으로 지정된다.
pd.get_dummies(df)
위 함수의 결과로 우리가 얻고자 했던 결과대로 gender, car에 대해서만 인코딩이 되었다. 만약 숫자로 이루어진 범주형 변수들도 더미변수로 바꿔주고 싶다면 columns옵션을 통해서 직접 컬럼을 설정해줘야 한다. 이번엔 work_phone까지 지정해 보겠다.
pd.get_dummies(df, columns = ['gender', 'car','work_phone'])
여기서 car_N을 \(x_1\), 그리고 car_Y를 \(x_2\)라고 가정해 보겠다. 그러면 \(x_1 + x_2 = 1\)의 관계를 갖는다는 걸 알 수 있다. 즉, 두 변수가 완벽한 선형관계를 갖는다. 두 변수가 완벽한 선형 관계를 갖게 되면, 두 변수 중 하나는 아래와 같이 자동으로 드롭이 된다.
$$ x_1 + x_2 = 1 $$
$$ x_1 = 1 - x_2 $$
$$ \hat{y} = b_0 + b_1(1-x_2) + b_2x_2 $$
$$ = b_0 + b_1 + (b_2 - b_1)x_2 $$
$$ = \beta_0 + \beta_1x_2$$
이 중에 일반적으로 제외시키는 변수는 비교 기준으로 삼고자하는 그룹이다. 즉, 차를 소유한 사람인 car_N을 기준으로 삼고자 한다면, \(x_1\)을 제거한다. pd.get_dummies() 함수에는 이렇게 기준이 되는 더미변수 하나를 제외시키는 옵션이 있다. drop_first=True옵션이다. gender, car, work_phone 3개의 컬럼이 모두 완벽한 선형관계를 갖기 때문에 3개의 독립변수에 대해 모두 drop_first 옵션을 줘보겠다.
pd.get_dummies(df, columns = ['gender', 'car','work_phone'], drop_first=True)
그러면 이러한 결과가 나온다. 이번에는 OneHotEncoder() 방법에 대해서 알아보자.
3. OneHotEncoder()
get_dummies() 함수와 똑같이 더미변수로 바꿔 줄 범주형 컬럼을 생성해 주는 함수이다. 결정적인 차이점은 OneHotEncoder() 함수는 train 데이터셋과 test 데이터셋의 범주 개수가 다른 경우에, test 데이터의 범주 개수를 train 데이터셋에 맞춰서 똑같이 생성할 수 있다는 점이다.(만약 이러한 경우 get_dummies() 함수로 원-핫 인코딩하여 학습시키면 오류가 발생한다.)
바로 코딩을 해보면서 이해해 보자. car이라는 컬럼을 OneHotEncoder()를 활용해서 원-핫 인코딩을 해볼 것이다. car의 컬럼은 N과 Y의 유니크 값들이 저장되어 있다.
label = df['car']
label.unique() # array(['N', 'Y'], dtype=object)
Sklearn의 OneHotEncoder를 불러와서 ohe라는 변수로 지정해 주었다. sparse=True가 디폴트인데, 이는 행렬(Matrix)을 반환한다. 원-핫 인코딩에서는 벡터(array)가 필요하므로 sparse=False를 넣어준다.
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(sparse=False)
OneHotEncoder의 주의할 점은 numpy 행렬을 입력해야 학습이 된다는 점이다. 또한, 벡터 입력을 허용하지 않는다. pandas의 Column 형태에서 인덱스를 뺀, values값만 추출해서 벡터로 만들고, 그 벡터를 다시 reshape을 통해서 행렬 형태로 변환해주야 한다.
label.values
# array(['N', 'Y', 'Y', 'Y', 'N', 'N', 'N', 'Y'], dtype=object)
label.values.reshape(-1,1)
# array([['N'],
# ['Y'],
# ['Y'],
# ['Y'],
# ['N'],
# ['N'],
# ['N'],
# ['Y']], dtype=object)
이렇게 변환한 형태를 fit함수를 통해 OneHotEncoder에 학습시켜서 범주를 찾아낸다.
ohe.fit(label.values.reshape(-1,1))
transform 함수를 사용하면, df['car']의 범주가 학습된 OneHotEncoder를 다시 배열 형태로 반환해 준다.
ohe.transform(label.values.reshape(-1,1))
# array([[1., 0.],
# [0., 1.],
# [0., 1.],
# [0., 1.],
# [1., 0.],
# [1., 0.],
# [1., 0.],
# [0., 1.]])
테스트로 범주를 'N' 하나만 가지고 있는 label_test라는 새로운 데이터를 넣어보겠다.
label_test = np.array([['N'],['N']])
# array([['N'],
# ['N']], dtype='<U1')
ohe.transform(label_test)
# array([[1., 0.],
# [1., 0.]])
그럼 이렇게 범주가 한 개만 있는 데이터라도 기존에 두 개의 범주를 가지고 있던 데이터와 똑같이 두 개의 범주를 가지고 있는 형태의 배열을 만들어준다. 그래서 train data와 test data의 범주의 수가 다른 대용량 데이터 같은 경우에는 pd.dummies()가 아닌, OneHotEncoder()을 사용해야 하는 것이다.
이제 이렇게 더미변수로 바뀐 컬럼을 기존 데이터 프레임에 합쳐주는 작업만 하면 끝이다. 그전에 tranform의 결과만 보면, 첫 번째 열과 두 번째 열이 어떤 범주를 나타내는지 명확하게 알 수 없으므로, categories_함수를 활용해서 한 번 더 체크해주어야 한다.
ohe.categories_
# [array(['N', 'Y'], dtype=object)]
첫 번째 열이 'N'이고 두 번째 열이 'Y'인 것을 확인했다. 인코딩 된 행렬을 다시 데이터 프레임으로 바꿔주고, 컬럼 이름을 구분할 수 있게 'car_N', 'car_Y'로 지정해 준다.
label_ohe = ohe.transform(label.values.reshape(-1,1))
ohe_df = pd.DataFrame(ohe_label, columns=['car_N', 'car_Y'])
ohe_df
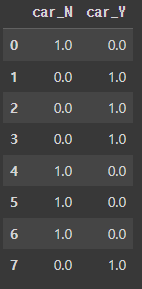
이제 이 데이터프레임을 pd.concat() 함수를 통해서 기존 데이터프레임과 합쳐주겠다. 그리고 기존에 원-핫 인코딩이 되어있지 않던 car 컬럼은 제거해 주겠다.
pd.concat([X, ohe_df], axis=1).drop('car', axis=1)

이렇게 원-핫 인코딩을 하는 방법에 대해서 알았다. 간단한 방법은 pd.dummies() 함수를 이용하면 되고, train 데이터와 test 데이터의 범주가 다른 대용량 데이터의 경우에 사용해야 하는 OneHotEncoder()를 사용해야 한다.
그렇다면, 위 데이터 프레임에서 male, female 이렇게 딱 2개로 특정되어 있는 데이터는 더미변수 칼럼을 따로 만들지 않고, 그냥 간단하게 숫자 0,1로 바꿔버리는 방법은 없을까? 일, 이, 삼, 사 이런 식으로 연속형 데이터인데, 숫자가 아닌 문자로 되어있는 데이터의 경우에도 1,2,3,4,5 이렇게 변환시키는 방법은 없을까? 물론 방법이 있다! 바로, LabelEncoder와 OdinalEncoder이다. 이 방법에 대해서 다음에 한 번 다뤄보겠다.
'머신러닝,딥러닝 > ML 회귀분석(이상엽 교수님)' 카테고리의 다른 글
| 분류문제 성능평가 지표: Accuracy, Recall, Precision, F1 score (+titanic 실습) (1) | 2023.06.10 |
|---|---|
| [로지스틱 회귀] Solver 종류와 장단점 (2) | 2023.06.07 |
| 로지스틱 회귀 모형: 함수 개념 및 코딩 실습 (0) | 2023.05.29 |
| 회귀모델: 라쏘(Lasso), 릿지(Ridge), 엘라스틱 넷(ElasticNet) (0) | 2023.05.29 |
| 피처 스케일링: 표준화, min-max 정규화(feat. 파이썬) (0) | 2023.05.28 |



댓글