해당 글에서는 BeautifulSoup을 사용해서 정적 크롤링을 하는 방법에 대해서 알아본다. 크롤링 실습을 하기 전에 기본적인 웹 동작 원리에 대해서 알아야 하기 때문에 이론 적인 부분 먼저 설명한다. 대표적인 get과 post 방식 크롤링을 실습한다.
웹 동작 원리
크롤링은 웹사이트의 정보를 수집하는 과정이다. 따라서 웹이 어떻게 동작하는지 이해할 필요가 있다. 클라이언트란 데스크톱이나 휴대폰과 같은 장치이다. 혹은 크롬이나 파이어폭스와 같은 소프트웨어를 의미한다. 서버는 웹사이트와 앱을 저장하는 컴퓨터를 의미한다.

클라이언트가 특정 정보를 요구하는 과정을 요청(Request)이라고 하며, 서버가 해당 정보를 제공하는 과정을 응답(Response)이라고 한다. 클라이언트와 서버가 연결되어있지 않다면 둘 사이의 정보를 주고받을 수가 없다. 그래서 이를 연결하는 공간이 필요한데, 그것이 바로 '인터넷'이다. 건물에도 고유의 주소가 있는 것처럼 각 서버에도 고유의 주소가 있는데 이것이 인터넷 주소 혹은 URL이다.
클라이언트가 각기 다른 방법으로 데이터를 요청한다면 서버는 해당 요청을 알아듣지 못하게 된다. 그래서 이를 방지하기 위해 교정된 약속이나 표준에 맞춰서 데이터를 요청해야된다. 이러한 약속을 HTTP라고 한다. HTTP 요청 방식은 크게 GET, POST, PUT, DELETE가 있다. 크롤링에서는 GET과 POST 방식 2개만 주로 사용되므로 이 2가지에 대해서 알아볼 것이다.
1. GET 방식
get 방식은 인터넷 주소를 기준으로 이에 해당하는 데이터나 파일을 요청하는 것이다.주로 클라이언트가 요청하는 쿼리를 &나 ?형식으로 결합해서 서버에 전달한다. 예를 들어서 네이버에서 '코딩'이라고 검색을 해보자. 그러면 주소 끝부분에 쿼리는 '코딩'이라고 입력이 됐고, 해당 페이지에 내용을 보여주게 된다.

2. POST 방식
post 방식은 사용자가 필요한 값을 추가해서 요청하는 방법이다. get 방식과는 달리 클라이언트가 요청하는 쿼리를 body에 넣어서 전송하므로 요청 내역을 직접 볼 수가 없다. 동행 복권 홈페이지에 접속해서 당첨 결과 회차별 당첨 번호를 누르면, 화면을 바뀌어도 URL은 아무 변화가 없는 걸 알 수 있다.
따라서 post 방식의 데이터 요청 과정을 살펴보려면, 개발자 도구를 이용해야한다. F12를 누르고, Nerwork 탭을 선택한 후, '조회'를 클릭해 보면, 브라우저와 서버 간의 통신 과정을 살펴볼 수 있다.

맨 위 gemeResult ~~ 라고 나와있는 게 당첨 번호를 요청하는 건데, 이걸 클릭한 후 Header 탭을 보면, Request URL이 보인다. 이는 서버 주소를 의미한다. 그 아래 Request Method는 POST 방식이라는 걸 확인할 수 있다.

또한, Payload 탭에서 Form Data를 보면, 서버에 데이터를 요청하는 내역이 나와있다. 아래 2개의 값이 요청한 '회차'에 해당하는 데이터이다.


정리
get 방식은 입력항목에 따라 웹페이지 주소가 변경된다. post 방식은 입력항목에 따라 웹페이지 주소가 변경되지 않으므로 개발자 도구를 통해 확인해야 한다.
BeautifulSoup 모듈을 이용한 정적 크롤링 실습 순서
1. request 패키지의 get() 혹은 post() 함수를 이용해 데이터를 요청하여 HTML 정보를 가져온다.
2. bs4 패키지의 함수들을 이용해 원하는 데이터를 찾는다.
3. 데이터를 클렌징한다.
실습 : GET 방식
1. request 패키지의 get() 혹은 post()함수를 이용해 데이터를 요청하여 HTML 정보를 가져온다.
import requests as rq
url = 'https://quotes.toscrape.com/'
quote = rq.get(url)
quote #결과 : <Response [200]>
get방식으로 작동하는 사이트에서 크롤링을 할 땐, get함수를 사용한다. 위코드를 실행하면, HTTP상태코드 200이 뜨는데, 이는 응답을 정상적으로 처리했다는 뜻이다.
quote.content #결과 : HTML 정보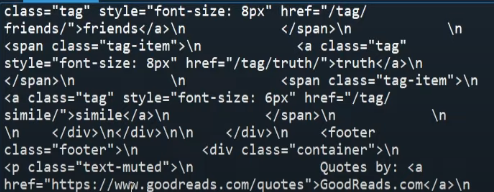
content는 HTML정보를 불러오는 함수다. 위 이미지와 같은 결과가 나오는데, 이는 텍스트 형태이므로 크롤링을 하기에 적합하지 않다. 따라서 크롤링을 하기 쉬운 형태로 바꿔주어야 한다.
from bs4 import BeautifulSoup
quote_html = BeautifulSoup(quote.content)
quote_html
위에서 HTML정보가 텍스트 형태로 출력되었던 content를 BeutifulSoup 함수에 넣어주면, 아래와 같이 HTML 요소에 접근하기 쉬운 형태의 결과로 출력된다.
2. bs4 패키지의 함수들을 이용해 원하는 데이터를 찾는다.
quote_div = quote_html.find_all('div', class_ = 'quote')
quote_div
bs4 패키지의 find_all() 함수를 사용해서 태그와 class명을 입력하면, 해당 태그와 class명과 일치하는 부분을 전부 찾아준다.
3. 데이터를 클렌징한다.
- find_all()함수
quote_div[0].find_all('span', class_ = 'text')[0].text위와 같이 코드를 작성하면, 결과로 출력되었던 부분 중에 첫번째 div태그 부분을 선택하여 그 안에서 다시 span태그에 class명이 'text'인 부분을 찾아준다. 그리고 [0]을 붙여주면, 첫 번째 텍스트 내용만 출력이 된다.
첫번째 코드와 두번째 코드를 합치면?
[i.find_all('span', class_ = 'text')[0].text for i in quote_div]
리스트 컴프리헨션을 통해서 이렇게 간단하게 코드를 작성할 수 있다. 그런데, find_all() 함수같은 경우엔 태그를 두 번 찾아서 들어가는 번거로움이 있다. 만약 데이터가 존재하는 곳의 태그를 여러 번 찾아야 하는 경우, find_all() 함수보다는 select() 함수를 사용하는 것이 더 효율적이다.
- select()함수
quote_text = qoute_html.select('div.qoute > span.text')
[i.text for i in qoute_text)
select 함수를 사용하면 이렇게 코드를 한 번만 작성하면 된다. 속성 값을 추출하고 싶은 경우에는 아래와 같이 코드를 작성하면 된다.
qoute_link = qoute_html.select('div.qoute > span > a')
[i['href'] for i in qoute_link)]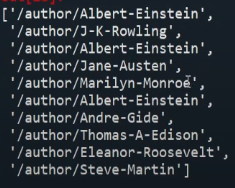
- pd.read_html() 함수
테이블만 크롤링하는 경우에는 코드가 더 간단하다. 태그와 클래스를 일일히 찾을 필요없이 판다스의 read_html()함수를 통해서 한번에 테이블 데이터를 추출할 수 있다.
import pandas as pd
url = 'https://en.wikipedia.org/wiki/List_of_countries_by_stock_market_capitalization'
tbl = pd.read_html(url)

실습 : POST방식
POST방식은 위에서 설명했던 것처럼 URL이 바뀌지 않기 때문에 개발자 도구 화면에서 Network 탭에서 Headers부분과 Payload 부분의 데이터를 아래와 같이 입력해주어야한다.
import requests as rq
from bs4 import BeautifulSoup
import pandas as pd
url = 'https://kind.krx.co.kr/disclosure/todaydisclosure.do' # Network -> Headers -> Request URL
payload = { # Network -> Payload (입력값 없으면 입력X)
'method': 'searchTodayDisclosureSub',
'urrentPageSize': '15',
'pageIndex': '1',
'orderMod': '0',
'orderStat': 'D',
'forward': 'todaydisclosure_sub',
'chose': 'S',
'todayFlag': 'N',
'selDate': '2024-03-13'
}
data = rq.post(url, data = payload)
html = BeautifulSoup(data.content)
html
이 경우엔 엑셀 데이터가 html 형태로 변경되어서 조금 복잡한 형태이다. 그래서 이걸 변형해서 데이터 프레임 형태로 볼러와 볼 것이다.
html_unicode = html.prettify()
html_unicode

prettify함수를 사용하면 BeautifulSoup에서 파싱 한 파서 트리를 다시 유니코드 형태로 돌려준다. 이걸 다시 판다스 함수를 활용해서 데이터 프레임 형태로 변경하면 끝이다.
pd.read_html(html_unicode)
이렇게 하면 테이블 데이터를 추출할 수 있다.
참고
'데이터분석 > 크롤링' 카테고리의 다른 글
| 파이썬 퀀트투자(3): 한국거래소 개별종목 지표 크롤링 (3) | 2024.10.09 |
|---|---|
| 파이썬 퀀트투자(2): 한국거래소 업종 분류 현황 크롤링 (1) | 2024.10.09 |
| 파이썬 퀀트투자(1): 최근 영업일 기준 데이터 크롤링 (7) | 2024.10.09 |
| 파이썬 웹 크롤링 환경세팅(VScode, miniconda, selenium) 및 예시코드 (0) | 2023.12.10 |
| Selenium 모듈 설치 및 크롤링 환경세팅 (0) | 2023.04.19 |




댓글