실무에서 일하는 사람들도 백테스트를 할 때, 흔히 저지르는 실수들
<퀀트 투자와 7대 죄악>
1. 생존 편향
2. 미래참조 편향
3. 스토리텔링의 죄악
4. 데이터 마이닝과 데이터 스누핑의 편향
5. 신호의 감소와 회전율
6. 이상치
7. 비대칭적 패턴과 공매도 비용
1. 생존 편향
- 생존 편향은 투자자들이 흔히 저지르는 실수
- 편의를 위해(혹은 데이터를 구하지 못해) 현재 상장된 회사만을 사용하여 투자 전략을 백테스트
- 파산, 상장폐지 또는 인수로 인해 투자 유니버스에서 사라진 주식은 백테스트에 포함하지 않음
- 생존 편향은 종종 지나치게 좋은 결과를 보여주거나 때로는 실제와 완전히 반대되는 결과를 보여줌
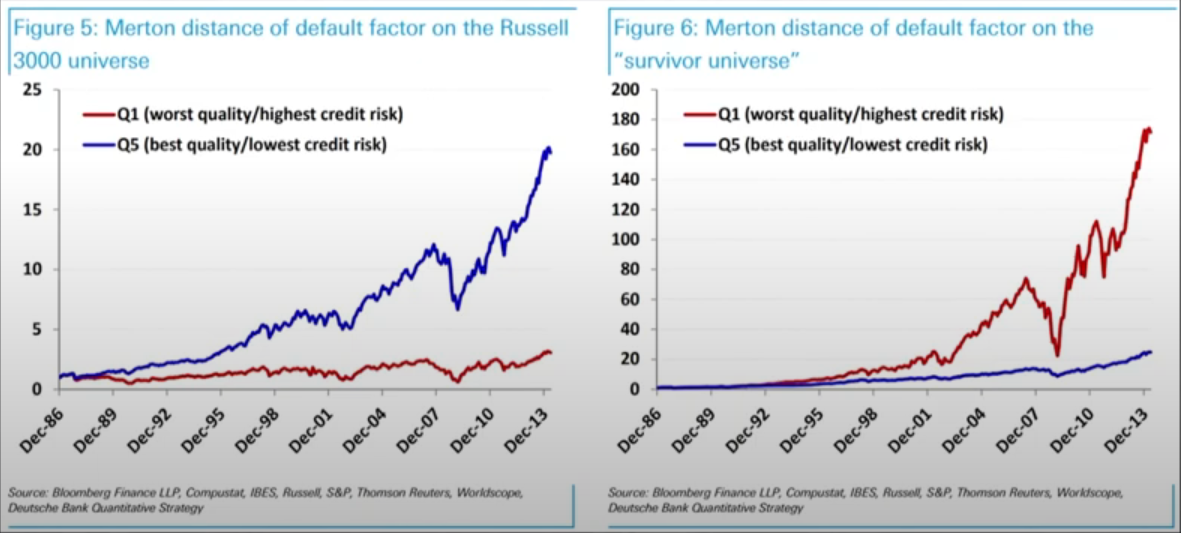
- 그림 3: 1986년 12월 31일에 Russell 3000 지수에 있었고 오늘날까지 살아남은 회사. 지난 28년 동안 지수의 3,000개 주식 중 500개 미만의 주식만이 살아남음.
- 지수에서 제외된 주식은 대부분 파산, 상장폐지 또는 장기간의 실적 부진으로 인한 것이기 때문에 살아남은 주식들의 평균은 전체 지수보다 월등히 우수함.

- Russell 3000의 전체 주식과 생존 편향이 있는 주식을 대상으로 머튼의 부도 팩터로 구성된 상위 및 하위 포트폴리오의 성과
- 생존 평향으로 인해 그림 5,6 같이 완전히 반대되는 결과가 나타남.
- 파랑색 : 우량성이 높은 종목
- 빨강색 : 우량성이 낮은 종목
- 백테스트에서 현재 지수의 구성 종목만을 사용하는 것은 현재 구성 편향의 영향을 받음
- ex) 2023년에 코스피 200에 포함된 종목을 과거에도 코스피 200에 포함되었다고 가정하고 백테스트를 돌려버리는 것.
- 일반적으로 실적이 저조한 종목은 지수에서 제외되고 실적이 우수한 종목은 지수에 추가됨
- 현재 지수의 종목을 백테스트에서 과거 시점에 사용하는 것은 미래에 성과가 좋을 회사(지수에 추가될 회사)에 대해 미리 알고 있음을 의미.
- 변동성이 낮은 주식이 변동성이 높은 주식보다 성과가 뛰어난 변동성 이상현상이 존재
- 그림 9 : 각 시점마다 S&P500에 포함된 종목을 가지고 수익률을 측정(정상)
- 그림 10 : 현재 S&P500에 포함된 종목을 가지고 과거부터 백테스트 한 결과(오류)
- 빨강색 : 저변동성
- 파랑색 : 고변동성
- 현재 S&P500 지수에 포함된 주식을 사용하면 정확히 그 반대 결과가 나옴.
- -> 모든 상승에 대해서는 포착하지만 하락에 대해서는 고려하지 않음.

- 생존 편향(현재 구성 편향)을 피하기 위해 해야할 것
- 백테스트용 유니버스는 상장폐지된 기업을 모두 포함해야 함
- 지수(예 : S&P500, MSCI World)를 사용하는 경우
백테스트 시점에 지수에 포함된 종목만을 사용해야 하며, 나중에 지수에 추가된 종목은 제외해야 함.
2. 미래참조 편향
- 백테스팅이 수행되는 시점에 알려지지 않았거나 사용할 수 없는 정보 또는 데이터를 사용하여 발생
- 기업들의 재무제표 데이터에는 미래참조 편향이 있는 경우가 많음.
- 회사들은 분기별, 반기별 또는 매년 재무 상태를 보고함
- 기업이 회계연도가 끝난 뒤 재무제표를 작성해 공시하는 데는 평균 1~2개월이 걸리며, 간혹 더 오래 소요되는 경우도 있음(중소기업의 경우 3개월 꽉 채워서 발표하기도 함)
- 그림 12 : 미국 기업의 분기 재무제표를 발표하는데 걸리는 기간 (평균 28~30일)
- 그림 13 : 전 세계 기업의 분기 재무제표를 발표하는데 걸리는 기간 (평균 35~37일)

- 일반적으로 백테스트에는 시간 지연을 적용
- 회계 기간 종료 후 x개월 후까지는 재무제표를 알지 못한다고 가정
- 일반적으로는 백테스트에서 3개월의 시간 지연을 적용
- 보다 복잡한 형태의 미래참조 편향은 재작성 편향
- 기업들은 종종 다양한 이유로 재무제표를 다시 작성함
- 일반적으로 사용되는 많은 데이터 소스는 최종적으로 수정된 데이터만 저장
- 재작성 편향을 해결하는 이상적인 해결책은 공급업체가 원래 보고된 데이터와 날짜를 보관 하고, 데이터가 수정될 때 마다 이를 추적하는 PIT(point-in-time) 데이터베이스를 사용하는 것
- 최초 발표 및 수정 시점이 모두 저장되기 때문에 좀 더 실제에 가까운 백테스트가 가능.

- 팩터 프리미엄을 평가하기 위해 사용하는 일반적인 접근법 중 하나는 IC(information coefficient)
- 1) 주어진 날짜의 팩터 점수를 기반으로 한 주식의 순위(ex. PBR을 기준으로 1등 부터 2000등까지 순위 구함)
- 2) 다음 기간(일반적으로 다음달)의 수익률을 기반으로 한 주식의 순위 간의 상관관계
- PBR 기준으로 상관관계가 1이 나오면, PBR을 보고 투자하는게 다음달 수익률을 예측하는데 좋은 지표라고 생각할 수 있음. 즉, IC 값이 높을 수록 좋은 팩터.
- PIT가 아닌 데이터, 즉 편향된 데이터는 밸류 팩터의 성과를 약 60% 가량 부풀림
- 그림 14 : PIT가 아닌 데이터로 백테스트 -> IC 값이 평균 8.12%
- 그림 15 : PIT 데이터로 제대로 된 백테스트 -> IC 값이 평균 5.11%

- PIT 데이터를 사용할 수 없을 때, 투자자들은 일반적으로 일종의 보고 지연을 적용
- PIT 데이터는 가격이 너무 비싸기 때문에 쉽게 사용할 수 없음. 또한, 데이터가 있어도 핸들링이 어려움.
- 보고 지연 : 재무제표를 몇개월 뒤부터 확인하고 쓸 수 있는가에 대한 가정
- 지연을 너무 짧게 설정한다면, 잠재적으로 미래 참조 편량을 겪게 됨.(ex. 1개월)
- 지연을 너무 길게 설정하면 너무 오래된 데이터를 사요할 수 있음.(ex. 6개월)
- 지연 가정을 1개월에서 3개월로 연장함에 따라 ROE 팩터의 성과는 9% 감소
- 성과가 나빠져도 3개월 정도 보수적으로 지연을 주는 것이 현실에 가까운 백테스트

- 분할 조정 계수는 잠재적으로 미래참조 편향을 생성할 수 있음
- 분할 조정 계수란? 예를들어, 삼성전자는 250만원이던 주가가 액면분할로 인해 5만원이 됨. 그러면 수정주가를 계산하기 위해서는 과거 250만원에 1/50을 곱해야 됨. '1/50'이라는 값이 분할 조정 계수를 의미.
- 회사는 유동성을 개선하거나 특정 유형의 고객을 유치하기 위해 주식 분할
- 분할 조정된 데이터(예: 수정주가, 수정BPS)를 사용하면 상당히 미묘한 형태의 미래참조 편향이 발생할 수 있음
- 예를 들어, 수년에 걸쳐 여러 주식 분할을 한 주식은 수정주가가 매우 낮음(대표적 사례 : 테슬라)
- 기업들은 일반적으로 주가가 유동성에 부정적인 영향을 미칠 정도로 높은 수준으로 상승했기 때문에 주식분할을 선택
- 그런데, 백테스트에서 수정주가 기준 '저가' 주식을 산다는 것은 향후 25년 동안 분할될 주식을 미리 알고 사는 것을 의미
- 이러한 정보는 과거 시점에서 주식을 투자할 당시에는 분명히 알지 못하는 사실
- S&P500 지수에서 가격이 가장 낮은 25개 종목의 누적 성과(흔히 '꽁초 전략'이라고 불림 )
- 수정 주가를 사용할 경우 수익률이 2.5배 좋으며, 샤프 지수는 30%가 더 좋음(실제 S&P500 주가와 차이가 크게 나타남) - 파란색 그래프
- 실제 주가 기준 '꽁초' 전략 구현 - 빨간색 그래프
- 수정주가를 사용하면 수익률이 좋게 나오는 이유는 과거 시점에서 수정주가가 낮은 종목을 선택한다는 뜻은 그 종목이 미래에 수익률이 굉장히 좋아서 주가가 오르고, 그것 때문에 액면분할을 할 주식이라는 점을 미리 알고서 투자한다는 가정이기 때문.
- 낮은 가격의 주식을 사는 것이 좋은 전략이라는 잘못된 결론을 쉽게 도출

- 백테스팅을 제대로 하는 적절한 방법은 조정되지 않은 가격, 즉 투자 당시의 "원래" 가격을 사용하는 것
- 그림 19 : 수정주가가 아닌 현실에 가까운 원래 가격을 사용하면, S&P500 지수와 크게 차이나지 않음
- 그림 20 : 샤프지수 관점에서는 오히려 꽁초전략이 변동성이 너무 높기 때문에 S&P500보다 샤프지수가 월등히 낮은 전략
- 그래서 제대로 백테스트를 할려면 지표를 계산할 때는 일반적인 주가(원래 데이터)를 사용하고, 지표를 기준으로 투자 수익률을 측정할때는 수정주가를 사용해야함.
- '저가' 주식의 연간 수익률은 벤치마크와 거의 같지만 변동성을 두 배 이상
- -> 저가 주식을 사는 것은 전혀 좋은 전략이 아님

- 미래참조 편향을 피하기 위해 해야할 것
- 가능한 한 PIT 데이터를 사용
- PIT 데이터를 사용할 수 없을 경우, 보수적으로 (3개월 정도의)지연을 설정
- 분할조정(ex. 수정주가)을 사용할 경우 조심할 것
- 백테스팅 결과가 직관에 어긋날 때는 다시 생각할 것
- 가장 좋은 건, 전략을 실시간으로 실행하여 성과가 백테스트와 일치하는지 확인할 것
3. 스토리텔리의 죄악
- 이해할 수 있고 직감을 가지고 있는 것에 투자하는 것이 더 편함
- 문제는, 일단 패턴을 찾으면 거의 항상 그것을 설명할 이야기를 생각해 수 있음
- 그러나 무언가를 설명할 수 있다는 사실은 그것의 표본 외 성과와는 아무 상관이 없음
- 재무 레버리지가 높은 기업(예: 장기 부치/총자산)에 따라 수익률에 차이가 있는가?
- 레버리지가 높은 기업이 본절적으로 더 위험하다고 주장할 수 있으므로, 더 높은 요구 수익률이 필요
- 행동재무의 스토리텔링을 통해 레버리지가 높은 회사의 수익률이 낮아야 하는 이유도 찾을 수 있음
- 부채/총자산(혹은 부채/자본) 비율에 관한 백테스트를 할 경우, 시점이나 유니버스에 따라 성과가 상이하게 나타남
- 확증 편향: 이전 믿음을 뒷받침하는 정보를 찾고 그렇지 않은 정보는 무시
- 새로운 데이터에 대한 일반적인 비판 : "데이터가 불과 몇 년 밖에 되지 않으며 역사가 충분히 길지 않다"
- 물리 과학과 달리 경제 및 금융 분야에서는 시간에 따른 관측치가 하나만 존재(실험이 불가능하기 때문)
- 데이터가 정상성이 있더라도 월간 단위로 긴 데이터, 혹은 일이나 틱 단위로 적당한 기간의 데이터가 필요
- 작은 표본에서 오는 편향을 극복하기 위해 최소한 몇 번의 경제 사이클에 백테스트를 적용해야
- 그러나 문제는 경제 데이터가 종종 비정상성이 있다는 것을 알고 있으며 따라서 20년 전(또는 심지어 몇 년 전)에 일어난 일은 오늘날과 관련이 없을 수 있음
- 국면이 바뀌는 것은 금융에서는 흔한 일
- 그림 22 : 1987년부터 1997년까지는 벨류 팩터의 성과가 굉장히 좋은 것으로 나옴.
- 그림 23 : 1997년 말부터 2000년 중반: IT 버블 기간의 기술 섹터에서 가치 전략은 -70% 손실
- 낡은 사업 모델이 곧 이른바 '새로운 경제'로 완전히 대체될 것이라는 믿음
- 사람들은 '닷컴'이라는 이름과 함께 가치가 더이상 무의미하다고 생각
- 그림 24 : 2000년 중반부터 2002년 후반: 가치 스타일이 강하게 회복(IT 버블 이후 기술 섹터에서 가치주 전략)
- 즉, 똑같은 가치 전략이 이간을 어떻게 보느냐에 따라 사람들은 거기에 맞는 스토리텔링을 적용함.

- 20년의 역사: 기술 섹터에서 가치 전략은 아무 효과가 없는 것 처럼 보임
- 기술 섹터에서 전형적인 가치 전략의 샤프 비율은 상당히 나쁘기도 하며 상당히 좋기도 함
- 대체 어떤 이야기를 믿어야 하는가?
- 더 큰 문제는 사람들이 '작동하는' 팩터만 발표하고 그렇지 않은 팩터는 무시하는 경향이 있음

- 기간 편향을 피하기 위해 해야할 것
- 가능한 한 오랜 기간을 사용하여, 가능한 한 많은 경제 및 정책 주기에 백테스트
- 그래서 최근에 발표되는 팩터 전략들은 100~200년 기간을 대상으로 백테스트
- 다양한 경제 사이클에서 성과가 어떻게 달라지는지 이해하고 정부 정책의 개입이 잠재적으로 새로운 레짐을 만드는지를 조사
- 가능한 한 오랜 기간을 사용하여, 가능한 한 많은 경제 및 정책 주기에 백테스트
4. 데이터 마이닝과 데이터 스누핑 편향
- 데이터 마이닝: 컴퓨터 과학 및 통계 분야에서 정교한 통계 기법, 게산 알고리즘 및 대규모 데이터베이스 시스템과 관련된 대규모 데이터 세트에서 패턴을 발견하는 계산 프로세스
- 금융에서는 애널리스트가 보여주고자 하는 패턴을 찾기 위해 데이터나 모델을 '조작'하는 것을 의미(=과최적화)
- 데이터 스누핑, 즉 표본 내 모델에 완벽하게 맞는 패턴이나 규칙을 광범위하게 검색하는 행동
- 모델의 변수를 미세하게 조정하고 백테스트에서 수익률이 높은 변수를 선택
- 충분하게 데이터 조작을 한다면, 인 샘플에서 매우 잘 작동하는 모델은 얼마든지 만들 수 있음
- 그림 28, 29 : 2009년 5월 31일부터 2014년 6월 30일까지 72개 팩터의 성과를 백테스트하고, 6개 스타일 버킷(가치, 성장, 모멘텀/반전, 센티먼트, 퀄리티, 기타)에서 각각 가장 좋은 팩터를 선택하고 6개 팩터에 동이라헥 가중치를 부여한 멀티 팩터 모델을 만듦
- 파랑색 그래프 : 2009년 이전에 성과가 좋았던 팩터를 선택한 후 2009년까지 투자. -> 성과가 굉장히 안좋음. 즉, 빨강색 그래프는 과최적화된 모델.
- 이러한 실수는 트레이딩 하는 사람들이 흔히 저지르는 실수
- 2009년 5월 31일부터 2014년 6월 30일까지 같은 기간 동안 이 모델의 성능을 백테스트

- 데이터 스누핑 편향을 피하기 위해 해야할 것
- 미래 참조 편향을 피하기 위해 모델과 백테스트 전략을 구축할 때 point-in-time 데이터 사용
- 한 국가의 주식 데이터와 같이 하나의 데이터 집합을 사용하여 모델을 구축한 후 동일한 방법을 변수에 대한 최적화가 없이 다른 국가나 지역에도 적용
- 단일 국가(예: 미국 주식 또는 일본 주식)를 다루는 경우, 일련의 표본 외 데이터를 준비. 절대로 "검즐 샘플"을 만지지 말고 최종 모델 성능을 확인하는 데만 사용
- 진정한 테스트는 실제 성과!
5. 신호의 감소와 회전율
- 백테스팅은 종종 거래 비용이 없고 회전율 제약이 없으며 무제한으로 롱숏이 가능하다고 가정
- 현실적으로 모든 투자자들에게는 제약 사항이 존재
- 신호가 빠르게 감소하는 팩터에서 매력적인 수익을 거두기 위해서는 상당한 회전율이 필요
- 높은 회전율은 더 많은 거래를 의미하며, 거래에는 비용이 발생
- 단기 반전: 최근에 실적(=수익률)이 좋았던 주식(예: 지난 달)이 그 다음 달에 하락할 가능성이 더 높음
- 반전 팩터는 수수료를 고려하지 않을 경우 상당히 훌륭한 주식 선택 전략
- 거래 당 비용을 Obps에서 30bps로 늘리면 PBR 팩터의 초과 수익은 완만하게 떨어지는 반면, 반전 전략의 알파는 음수로 떨어짐.
- 반전 전략은 매달 포트폴리오를 교체해야 하므로 회전율이 상당히 높음. 그래서 비용에 큰 영향을 받음.

- 빠른 신호 감소 및 높은 성과를 보이는 팩터
- 엄격한 회전율 제약 조건을 추가하여 거래 비용을 제한하면서 에측력을 포착할 수 있음
- 예측력과 감소 / 회전율, 비용 사이의 균형이 중요
- 탁월한 예측력을 가진 모델의 경우 거래 비용 후에도 많은 거래를 통해 더 높은 수익을 창출 할 수 있음.
- 현실적으로 모든 매니저가 원하는 만큼 거래할 수 있는 것은 아님
- 대부분의 기관 포트폴리오 관리자들은 어느 정도의 회전율에 대한 제약이 존재
- 회전율 제약 조건은 모델의 성과에 상당한 영향을 미칠 수 있음.
- 빨강색 그래프 : 회전율 제약 조건이 120%일 경우
- 제약이 떨어질 수록 성과가 훅 떨어
- 회전율 제약 조건은 모델의 성과에 상당한 영향을 미칠 수 있음.

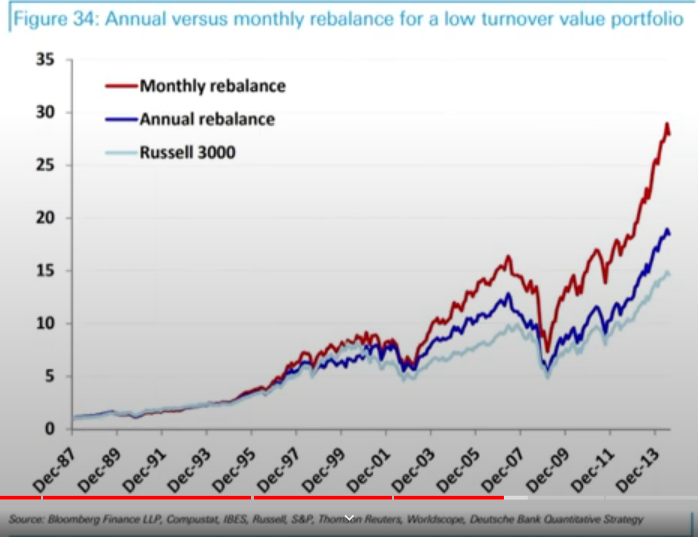
- 회전율 제약이 엄격하다고 해서 반드시 리벨런싱 빈도가 매우 느려야 한다는 뜻은 아님
- 연간 36% 이하의 상당히 엄격한 회전율 제약이 있는 롱-온리이면서 가치주에 틸트된 공모 펀트 포트폴리오를 운용한다고 가정
- Russell 3000 지수를 추종하면서 PER 팩터에 틸트를 하며, 연간 추적 오차를 4%로 제한
- 파랑색 그래프 : 1년에 한번 리밸런싱하는 펀드 수익
- 빨강색 그래프 : 월간 단위로 리밸런싱(월 3% 이하 제약)
- 즉, 리밸런싱 주기를 매월로 가져가고, 반면 한 번 리밸런싱을 할 때 회전율을 낮게 가져가는 전략이 좋음.
- 알파의 감소가 빠른 팩터는 높은 회전율을 요구하는 반면 회전율이 높으면 거래 비용이 더 많이 발생
- 일부 신호는 너무 빨리 감소하여 알파의 기회가 몇 시간, 몇 분 또는 몇 초 내에 사라짐
- 1일 반전 팩터(전날 가장 많이 하락한 주식을 사는 것)의 백테스트는 단기 반전이 훌륭한 전략처럼 보임
- 문제는 팩터 자체가 시장이 마친 후에만 계산될 수 있음
- 우리가 신호에 따라 거래할 수 있는 가장 빠른 시간은 다음 날 시장이 열릴 때
- 그래서 흔히 백테스트를 할 때, 전일 종가와 오늘 종가를 통한 수익률을 사용하여 팩터를 계산한 후 같은 날 종가에 거래(이론적으로만 가능) -> 빨강색 그래프
- 전일 종가와 오늘 종가를 통한 수익률을 사용하여 팩터를 계산한 후 그 후 다음날 시초가에 거래(현실적으로 가능) -> 파랑색 그래프(수익률이 형편없음)

6. 이상치 - 극단적인 성공과 실패
- 이상치는 재무 데이터에서 일반적으로 발생
- 이상치를 샘플에서 완전히 제거(트렁케이션/트림)하거나 원저화를 통해 제한을 할 수 있음
- 트렁케이션: 이상치를 삭제
- 원저화: 특정 x 백분휘 수(종종 5%, 1% 또는 0.1%로 설정)보다 크거나 작은 데이터를 x번째 백분위 수값으로 대체
- 이상치는 두 데이터 모두에서 분명히 하지만 아시아 ex 재팬에서 더 뚜렷하게 나타남
- 금융 데이터의 품질은 일반적으로 미국 기업이 글로벌 기업보다 우수
- 원저화의 간단한 방법은 -100% 미만의 이율을 - 100%로 대체 (100% 이상의 이율도 동일)

- Russell 3000 지수의 과거 12개월 이율: 모든 주식의 총 이율을 총 시가 총액으로 나누어 계산
- 기업의 펀더멘털 데이터를 시장 지수 수준으로 집계하면 이상치가 더 큰 영향을 미칠 수 있음.
- (아래 네모 영역) 이율이 너무 크거나 낮은 기업이 전체 값이 영향을 미침.
- 1% 수준에서 원저화를 한 후 집계하면 데이터의 흐림은 더욱 의미가 있는 것처럼 보임

- 한국 유니버스에서 동일하게 이율을 계산하면 매우 변동성이 크며 대부분의 기간에서 음수를 보임
- 1% 수준에서 윈저화하면 많은 변동폭이 사라짐
- 2%로 설정하면 대부분의 이상치가 사라지고 인덱스의 이율이 훨씬 더 부드러워 지지만 필연적으로 유용한 데이터도 제거될 수 있음.

- 윈저화를 할 때 고려사항
- 데이터 오류 또는 중요한 관측치인지 여부에 관계없이 데이터 샘플의 극단값을 제거. 이상치에는 실제로 유용하고 중요한 정보가 포함될 수 있음
- 임계 백분위 수(1% 혹은 2% 등)는 종종 주관적이고 임의로 선택되며 일률적인 해결책은 없음. 단일 팩터에 대해서도 이상치의 백분위수가 시간이 지남에 따라 변경될 수 있음. 그래서 윈저화를 할때 값을 기준으로 하는게 아닌 퍼센트를 기준으로 하는 것을 추천.
- 백테스트 결과는 우리가 선택한 컷오프 값에 민감할 수 있음.
- 사분범위(IQR: Inter-quartile range)를 통한 이상치의 제거
- 상위 사분위와 하위 사분위의 차이
- Q1과 Q3를 각각 하위 사분위와 상위 사분위라고 가정하고, Q3-Q1을 사분범위(IQR)라고 함
- 이상치는 범위를 벗어난 관측치로 정의되며, k는 음수가 아닌 상수
- [Q1 - k(Q3-Q1), Q3+k(Q3-Q1)]
- 데이터의 왜도가 크지 않는 한 관측치의 50%(각 측면의 25%)까지를 이상치로 제외할 수 있으며 이상치가 없는 경우 전체 표본을 유지

- 예를 들어 홍콩 시장의 Book-to-market(PBR의 역수)
- 원래 데이터(하늘색 그래프)를 사용할 경우 BtoM은 매우 극단적인 값을 보임.
- 이 값이 높다는 말은 PBR이 낮다는 뜻. 그런데 IT 버블 구간에 PBR이 낮은것은 이해가 안됨.
- 윈저화를 했음에도 불구하고 2002년 이전에는 BtoM이 25이상인 이상치가 존재
- 이걸 윈저화를 해도(파란색 그래프) BtoM이 25 이상(PBR이 지나치게 싼) 극단치가 존재. 그래서 홍콩 시장 전채의 BtoM도 높게 나타남(PBR이 낮음)
- 그래서 문제는 이상치에 대한 제어가 없거나 윈저화 기술을 사용하지 않으면 홍콩 시장은 2008년 글로벌 금융 위기때보다 2000년대 초반이 훨씬 저렴한 것 처럼 보임
- 4분 범위를 이용한 데이터 핸들링을 해주면(빨강색 그래프) 비로소 IT버블 구간에 BtoM이 낮게 나옴(PBR이 높음)
- 원래 데이터(하늘색 그래프)를 사용할 경우 BtoM은 매우 극단적인 값을 보임.

- Z-score 데이터 정규화
- 데이터를 정규화하는 가장 보편적인 방법은 Z-score를 사용
- 값을 평균으로 뺀 다음 그걸 변동성으로 나누어서 정규화하는 방법.
- 대부분의 팩터에 대해 z-score 변환 후에도 여전히 유의한 이상치가 있으며 분포는 여전히 정규분포가 아닐 수 있음
- 그래서 많은 애널리스트들은 이상치 제어를 추가로 적용(예 : 윈저화 또는 IQR 제거)
- 순위 변환
- 모든 주식의 팩터 점수를 기준으로 순위를 매김
- 순위 변환은 모든 분포를 균일 분포로 자동 변환
- 이를 통해 모든 이상치는 합리적인 데이터 범위로 변환
- 역정규변환(inverse normal transformation)을 한번 더 해줄 경우 팩터는 항상 평균이 0이고 표준편차가 1인 정확한 표준 정규 분포를 따르게 할 수 있음
- 인도네시아의 이율 팩터의 raw 데이터
- 데이터가 정규분포를 따르지 않고 이상치가 많음
- z-score 정규화를 거치면(그림 45) 이상치는 여전히 존재하지만, 분포의 왜도가 훨씬 줄어듦

- 그래서 여기다가 순위 정규화를 해주면 균등 분포를 보임
- 마지막으로 역정규변환(또는 z-score)을 해주면 표준정규분포로 모양이 바뀜.

- 세 가지 다른 데이터 정규화 기술을 사용하여 멀티팩터 모델의 성능을 비교
- 순위 변환은 대부분의 국가에서 Z-score 변환보다 성과가 우수
- 순위 변환을 기반으로 할 경우 모델간 신호의 평균 상관관계도 더 높음(회전율이 낮아짐)
- 빨간색 : 순위변환
- 파란색 : z-score
- 결과 - 랭킹을 기반으로 멀티팩터를 계산한 것의 IC가 더 높음
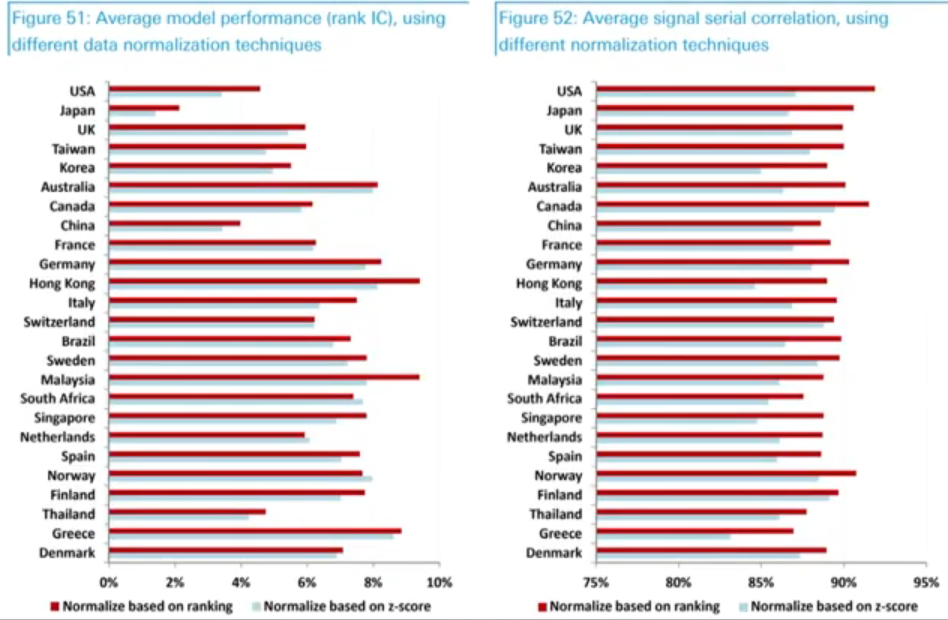
정규 방법별 IC
- 순위 변환의 문제는 팩터 점수들 간의 거리에 포함된 정보를 잃어버림
- 주식 A의 순위가 주식 B의 순위보다 높으면 A가 B보다 1% 높던지 20% 높던지 상관이 없게 됨
- 대부분의 팩터에서 순위는 중요하지만 거리는 소음 이상의 것을 추가하지 않음(즉, 순위만 봐도 되긴함)
- 단, 가격 모멘텀은 예외
- 모멘텀 점수 사이의 거리가 주식의 미래 수익에 대한 유용한 정보를 포함.
- ex. 어떤 주식의 수익률이 몇 퍼센트를 기록했다는 정보 등이 미래 수익에 대한 유용한 정보를 포함.
- 순위 변환을 하지 않은 원래의 가격 모멘텀의 수익률이 훨씬 더 높음
- 모멘텀 점수 사이의 거리가 주식의 미래 수익에 대한 유용한 정보를 포함.
- 가격 모멘텀 팩터의 성과
- 1) 순위 변환을 거치지 않은 원래의 가격 모멘텀 점수를 사용 - IC: 4.3%
- 2) 모멘텀 점수에 순위 변환 - IC: 2.8%
- 약 35%의 예측력 손실
- 가격 모멘텀 팩터를 정규화 함으로써 예측력에서 35%의 손실

왼쪽 : 순위 변환 X / 오른쪽 : 순위변환 O
7. 대칭적 패턴과 공매도 비용
- 팩터 성과를 측정할 때 일반적으로 두 가지 측정 기준을 살펴봄
- 롱/숏 수익률의 차이:
일반적으로 팩터 기준에 따라 첫 번째 분위수인 상위순위의 주식을 매수하고
동시에 최하위 분위수의 주식을 공매도하여 롱/숏 헤지 포트폴리오를 구성.
매수 (그리고 공매도) 포트폴리오의 주식은 동일 비중 혹은 시가총액 비중으로 가중.
분위수의 선택은 데이터 샘플의 크기에 따라 3 분위수, 4 분위수, 5 분위수, 10 분위수
롱/숏 포트폴리오는 주기적으로 리밸런싱- 예를 들어 PBR이 가장 낮은 종목 n개를 매수하고, 동시에 PBR이 가장 높은 종목 n개를 공매도해서 그 수익률을 롱/숏 헤지 포트폴리오의 성과를 통해 팩터의 성과를 측정.
- 순위 정보 계수(Rank information coefficient):
1) 주어진 날짜의 팩터 점수를 기반으로 한 주식의 순위
2) 다음 기간(일반적으로 다음달)의 수익률을 기반으로 한 주식의 순위 간의 상관관계를 살펴봄
해당 작업을 매 기간마다 반복- IC값이 높으면 팩터 점수가 향후 수익률 예측력이 있다고 판단.
- 롱/숏 수익률의 차이:
- 그런데 만약 팩터의 성과 패턴이 대칭적이고 선형적이며 단조롭다면, 두 방법 모두 비슷한 결론을 도출
- 수익 패턴이 비대칭적인 경우가 많음
- 매수와 공매도에 대한 성과를 별도로 측정하기 위해 다음 두 포트폴리오의 초과수익률을 계산
- 매수 포트폴리오의 초과 수익률: 투자 유니버스의 평균(혹은 중위수) 수익률 대비
상위 분위수 주식들을 동일 비중으로 매수한 포트폴리오의 수익률 - 공매도 포트폴리오의 초과 수익률: 투자 유니버스의 평규(혹은 중위수) 수익률 대비
하위 분위수 주식들을 동일 비중으로 공매도한 포트폴리오의 수익
- 매수 포트폴리오의 초과 수익률: 투자 유니버스의 평균(혹은 중위수) 수익률 대비
- 이율과 가격 모멘텀에 대한 매수와 공매도 포트폴리오의 초과 수익률
- 이율의 알파는 매수 포지션에 집중되는 반면 가격 모멘텀의 초과수익률은 공매도 포지션에 의해 좌우
- 가치 팩터는 정보 감소 / 회전율이 느릴뿐만 아니라 가격 모멘텀에 비해 알파를 포착하는 것이 더 쉬움
- 가치 프리미엄의 대부분은 공매도를 할 필요가 없이 매수를 통해서도 얻을 수 있기 때문에 단순히 매수를 통해서도 가치 프리미엄을 얻을 수 있음.
- 밸류 팩터의 경우 롱 포트폴리오의 수익률이 좋고(왼쪽 파란색 그래프), 숏 포트폴리오의 성과는 거의 없음(왼쪽 빨강색 그래프)
- 모멘텀 팩터의 경우 롱 포트폴리오의 수익률은 거의 없고(오른쪽 파란색 그래프), 숏 포트폴리오의 수익률이 굉장히 큼(오른쪽 빨강색 그래프), 즉 떨어지는 주식에 숏을 쳐서 얻는 수익이 큼. 현실적으로 공매도를 하기는 굉장히 어려움

왼쪽 : PER(밸류 팩터) / 오른쪽 : 가격 모멘텀(모멘텀 팩터)
- 미국의 28가지 팩터에 대한 매수와 공매도의 초과 수익률
- "공매도 포트폴리오의 초과 수익"과 "매수 포트폴리오의 초과 수익" 사이의 스프레드를 기반으로 정렬
- 상위에 있을 수록 공매도에 대한 수요가 많고 공매도 비용이 높기 때문에 알파를 포착하는 것이 어려움
- 파란색 : 숏 포트폴리오 수익률
- 빨간색 : 롱 포트폴리오 수익률
- 맨위는 모멘텀 팩터의 수익률을 나타냄. 모멘텀 팩터는 숏 포트폴리오에서 얻는 수익이 굉장히 큼
- 맨밑은 밸류 팩터의 수익률.
- Mean recommendation revision, 3M : 센티먼트 팩터의 수익률 -> 롱숏 대칭적
- 결론 : 아래 팩터들은 롱 포폴만으로도 수익을 낼 수 있음.
- 상위에 있을 수록 공매도에 대한 수요가 많고 공매도 비용이 높기 때문에 알파를 포착하는 것이 어려움

- 일반적인 백테스팅에서 비용이 들지 않거나 동일한 수준의 비용으로 모든 주식을 공매도할 수 있다고 가정
- 일부 주식의 경우 차입 비용이 엄청나게 높을 수 있으며, 차입이 불가능할 수 있음
- 특정 주식이나 산업 또는 국가의 경우, 공매도를 전면 금지하는 정부 또는 거래소 규칙이 있을 수있음
- Data Explorer는 전 세계 주식의 공매도의 가용성과 공매도 비용에 대한 정보를 제공(PIT 데이터)
- DCBS라 불리는 차입 비용은 매일 각 주식에 대해서 1에서 10까지의 숫자를 매김
- DCBS는 대출 기관이 부과하는 수수료를 나타내며,
1은 가장 저렴한 것을 의미하고 10은 가장 비싼 것을 의미.
- DSBS 점수 각각에 대한 비중
- 미국 주식의 거의 90%가 저렴한 혹은 쉽게 빌릴 수있는 것으로 분류
- 2008년 글로벌 금융위기 기간에는 차입비용이 급증하며, 일부 금융주는 공매도 되는 것조차 금지(빨간색 부분)

- 비현실적 포트폴리오: N-LASR 모델의 순위를 기반으로 상위 100개 주식을 매수하고 하위 100개 주식을 공매도.
모든 주식에 대해 공매도가 가능하다고 가정(빨간색 그래프) - 현실적 포트폴리오: N-LASR 모델의 순위를 기반으로 상위 100개 주식을 매수하고 하위 100개 주식을 공매도.
공매도 포지션에서는 DCBS 점수가 1점인, 즉 차입하기 쉬운 주식에 대해서만 공매도를 한다고 가정(파란색 그래프)
- 성과가 비현실적인 포트폴리오 대비 훨씬 낮아짐.

7대 죄악을 피하는 방법 정리
- 생존 편향: 상장 폐지된 종목을 고려하여 백테스트를 진행
- 미래참조 편향 : point-in-time 데이터를 사용
- 스토리텔링과 데이터의 역사 : 백테스트 기간을 길게 하며, 이를 통해 다양한 경제 환경에서의 성과를 살펴봄
- 데이터 마이닝과 데이터 스누핑 평향: 다양한 국가와 지역 그리고 자산군에 걸쳐 테스트
- 신호 감소와 회전율: 빠른 감소가 있는 팩터는 피하며, 포트폴리오의 성과는 수수료를 제하고 계산
- 이상치 제어: 멀티 팩터 모델로 합치기 이전, 각 팩터를 표준정규분포로 치환하기 위해 정규화 기술을 사용
- 비대칭적 성과와 공매도 비용: 공매도의 가용성으로 인한 영향을 자세히 살펴봄.
참고
댓글