빅분기 실기 작업형2 다중 분류 문제를 매우 간단하게 풀이할 수 있는 코드를 정리해보았다. tips 데이터로 다중 분류 문제를 만들어보았다.
1. 데이터 로드
import seaborn as sns
tips = sns.load_dataset('tips')tips 데이터를 로드해준다.
2. 결측치 제거
df = tips.dropna()
print(df.shape, tips.shape) # (244, 7) (244, 7)결측를 제거한다.
3. 인덱스 생성
df = df.reset_index()최종코드 제출시 인덱스 매칭이 필요하므로, 인덱스를 만들어준다.
4. 독립 변수, 종속 변수 분리
X = df.drop('day', axis=1)
y = df.day다중 분류 문제로 사용 가능한 day를 종속변수를 사용해주었다. day는 총 4가지 범주를 가지고 있다.
5. 학습, 테스트 데이터로 분리(층화추출)
# 학습, 테스트 데이터 분리(분류 문제에서는 stratify를 꼭 써줘야 균일하게 분리됨: 층화추출)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, stratify=y,random_state=42)
print(y_test.value_counts(normalize=True), y_train.value_counts(normalize=True))
"""
(day
Sat 0.351351
Sun 0.310811
Thur 0.256757
Fri 0.081081
Name: proportion, dtype: float64,
day
Sat 0.358824
Sun 0.311765
Thur 0.252941
Fri 0.076471
Name: proportion, dtype: float64)
"""학습, 테스트 데이터로 분리를 해준다. 맨 마지막에 제출한 데이터와 y_test를 비교해서 모델의 성능을 최종평가 하게 된다. 여기서 stratify로 y를 꼭 지정해주어야한다. 그래야 4가지 범주가 기존 비율에 맞게 층화추출이 된다. 만약 이 옵션을 사용하지 않으면, y_test에 'Fri'가 한개도 남아있지 않을 수도 있다.
6. 인덱스 분리
x_train_id = X_train.pop('index')
X_test_id = X_test.pop('index') # 제출시 사용제출시 인덱스 매칭이 필요하기 때문에 인덱스를 따로 분리해준다.
7. 숫자 컬럼, 문자 컬럼 분리
import numpy as np
num_cols = X_train.select_dtypes(include=np.number).columns
cat_cols = X_train.select_dtypes(exclude=np.number).columns
print(num_cols, cat_cols)
# Index(['total_bill', 'tip', 'size'], dtype='object') Index(['sex', 'smoker', 'time'], dtype='object')숫자 컬럼과 문자 컬럼을 분리해준다. 이 코드는 파이프라인 식 모델 학습 때 사용할 것이다.
8. 학습 데이터, 검증 데이터 분리(층화 추출)
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.2, stratify=y_train, random_state=42)제출 전, 모델의 성능을 확인하기 위해 학습 데이터와 검증 데이터를 분리해준다. 마찬가지로 꼭 층화추출을 해주어야한다.
9. 분류 모델 학습
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
column_transformer = ColumnTransformer([
('scaler', StandardScaler(), num_cols),
('ohc', OneHotEncoder(), cat_cols)
], remainder='passthrough')
pipe = Pipeline([
('preprocessing', column_transformer),
('cls', RandomForestClassifier(max_depth = 3, random_state=42))
])
pipe.fit(X_train, y_train)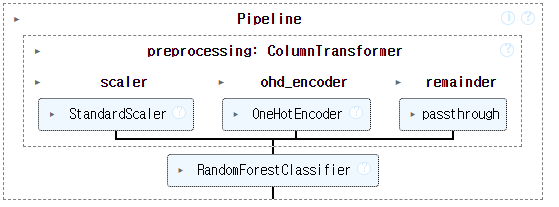
가장 중요한 코드이므로 꼭 외우길 추천한다. ColumnTrainsformer로 위에서 분리한 컬럼을 숫자 타입은 표준화 스케일러를 써주고, 문자 타입은 원핫 인코딩을 시켜준다. remainder='passthrough' 옵션을 사용하면, 숫자와 문자로 분리되지 않은 나머지 컬럼은 전처리를 하지 않고, 그냥 넘긴다는 뜻이다. 이 옵션을 사용하지 않으면, default 값이 'drop'으로 설정되어 있으므로, 나머지 열이 자동으로 삭제되어 모델이 학습되는 걸 방지할 수 있다. 전처리 대상이 아닌 열을 그대로 모델에 전달해야 하는 경우 꼭 사용해주어야한다.
파이프라인 코드를 사용하면, 매우 간단하게 모델을 학습시킬 수 있다. 모델이 학습되고 나면 이미지와 같이 어떤 프로세스로 모델이 학습되는지 한눈에 볼 수 있게 표현이 되므로 매우 유용하다.
10. 모델 성능 확인
from sklearn.metrics import accuracy_score, f1_score
tr_pred = pipe.predict(X_train) # 만약 확률로 구할시, predict_proba()[:, 1]
val_pred = pipe.predict(X_val)
tr_score = accuracy_score(y_train, tr_pred)
val_score = accuracy_score(y_val, val_pred)
print(tr_score, val_score)
"""
f1_score의 경우
tr_score = f1_score(y_train, tr_pred, average="macro")
val_score = f1_score(y_val, val_pred, average="macro")
print(tr_score, val_score)
"""tr_score가 높은데, val_score가 낮으면 과적합일 가능성이 높으므로, 하이퍼 파라미터를 조정해주면 된다.
11. 최종 코드 제출
# 최종 코드 제출
import pandas as pd
final_preds = pipe.predict(X_test)
result = pd.DataFrame({
"ID": X_test_id,
"spceis":final_preds})
result.to_csv("submission.csv", index=False)마지막으로 X_test로 예측된 결과물을 제출하면 된다. result가 y_test와 비교해서 어느정도 예측이 잘 됐는지를 평가받게 된다.
전체 코드
# 데이터 로드
import seaborn as sns
tips = sns.load_dataset('tips')
# 결측치 제거
df = tips.dropna()
print(df.shape, tips.shape) # (244, 7) (244, 7)
# 인덱스 생성
df = df.reset_index()
# 독립 변수, 종속 변수 분리
X = df.drop('day', axis=1)
y = df.day
# 학습, 테스트 데이터 분리(분류 문제에서는 stratify를 꼭 써줘야 균일하게 분리됨: 층화추출)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, stratify=y,random_state=42)
print(y_test.value_counts(normalize=True), y_train.value_counts(normalize=True))
"""
(day
Sat 0.351351
Sun 0.310811
Thur 0.256757
Fri 0.081081
Name: proportion, dtype: float64,
day
Sat 0.358824
Sun 0.311765
Thur 0.252941
Fri 0.076471
Name: proportion, dtype: float64)
"""
# 인덱스 분리
x_train_id = X_train.pop('index')
X_test_id = X_test.pop('index') # 제출시 사용
# 숫자 컬럼, 문자 컬럼 분리
import numpy as np
num_cols = X_train.select_dtypes(include=np.number).columns
cat_cols = X_train.select_dtypes(exclude=np.number).columns
print(num_cols, cat_cols)
# Index(['total_bill', 'tip', 'size'], dtype='object') Index(['sex', 'smoker', 'time'], dtype='object')
# 학습 데이터, 검증 데이터로 분리 : 층화 추출
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.2, stratify=y_train, random_state=42)
# 모델 학습
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
column_transformer = ColumnTransformer([
('scaler', StandardScaler(), num_cols),
('ohc', OneHotEncoder(), cat_cols)
], remainder='passthrough')
pipe = Pipeline([
('preprocessing', column_transformer),
('cls', RandomForestClassifier(max_depth = 3, random_state=42))
])
pipe.fit(X_train, y_train)
# 최종 코드 제출
import pandas as pd
final_preds = pipe.predict(X_test)
result = pd.DataFrame({
"ID": X_test_id,
"spceis":final_preds})
result.to_csv("submission.csv", index=False)
# 결과물 확인
df = pd.read_csv("submission.csv")
df.head()'데이터분석' 카테고리의 다른 글
| [빅분기 실기] 작업형1 문제 유형별 코드 정리 (0) | 2024.11.24 |
|---|---|
| [빅분기 실기] 모듈 이름, 함수 사용법 생각 안날 때 대처 방법 (0) | 2024.11.16 |
댓글